
|
Getting your Trinity Audio player ready...
|
Artificial Intelligence on Twitter:
An inside look at how Twitter used big data and artificial intelligence to moderate content
Twitter AI: The Role of Artificial Intelligence in Content Moderation
How does Twitter use artificial intelligence and machine learning?
Twitter uses large-scale machine learning and AI for sentiment analysis, bot analysis and detection of fake accounts, image classification and more.
From Amazon to Instagram, Sephora, Microsoft, and Twitter, AI will shape the future of speech in America and beyond. Every modern company leverages artificial intelligence.
The big question is not if they use it, but how it is being used, and what impact will this have on consumer privacy in the future.
Social Media content decisions have become highly political, and artificial intelligence has facilitated the moderation process at scale. But along the way, the public was left in the dark on just how large of a role machine learning plays in large-scale content operations in Silicon Valley.
Discussions about online content moderation rarely focus on how decisions by social media companies — often made with AI input — impact regular users.
Internal Twitter documents I obtained provide a window into the scope of the platform’s reliance on AI in the realm of political content moderation, meaning what phrases or entities were deemed misinformation and were later flagged for manual review. The documents show that between Sept 13, 2021-Nov 12, 2022, when political unrest was taking place, Twitter was flagging a host of phrases including the American flag emoji, MyPillow, Trump, and election fraud.
AN INSIDE GLIMPSE INTO THE INTERNAL MACHINE LEARNING PROCESSES OF TWITTER
Insider documents reveal unprecedented access and an inside look at how Twitter flagged political misinformation.
While much of the conversation around the so-called Twitter Files releases have focused on how government agencies sought to pressure Twitter into moderating content on its platform, the role of artificial intelligence has remained widely misunderstood.
Social Media content decisions today are aided by artificial intelligence, machine learning, and natural language processing. which helps facilitate moderation at scale. I spoke with a former Twitter Data Scientist, who previously worked at Twitter doing machine learning in US Elections and political misinformation on AI and machine learning. The former employee consented to this interview on the condition of anonymity.
Twitter created a data science team that was focused on combatting U.S. political misinformation. This new division was created after the 2016 election. The team was comprised of data scientists who frequently corresponded with Trust and Safety at Twitter as well as third party government agencies including The CDC to identify alleged political misinformation. Content moderation and Machine Learning at Twitter was directly influenced by third party government agencies, academic researchers, and Trust and Safety.
The Ruby Files reveals an inside look into how Twitters’ machine learning detected for political misinformation, and the word lists used in natural language processing.
I was granted access to internal Twitter documents by a former employee. These documents showed examples of words that were flagged for automated and manual removal by Twitter.
These company documents have never been previously published anywhere else. What follows is that discussion.
Worth a read
— Elon Musk (@elonmusk) December 10, 2022
EXECUTIVE SUMMARY:
ALGORITHMIC POLITICAL BIAS. Political bias was exhibited in Twitter’s training dataset in the U.S. Political Misinformation Data Science division that monitored election content. Multiple independent Data Scientists who reviewed the dataset confirmed this to be true.
UNINFORMED CONSENT FOR MACHINE LEARNING EXPERIMENTATION ON USERS. Twitter ran numerous Machine Learning experiments on users at any given time. Some of these experiments were ethically questionable. Users did not give consent, nor were they told that any of the experiments were happening. It is reasonable for a company to do A/B testing or Machine Learning experimentation as long as the process is transparent and users can opt-in or opt-out and know what they are participating in.
LACK OF PARAMETER TRANSPARENCY. A former Twitter Data Scientist alleged that the n-gram parameters pertaining to U.S. political misinformation were changed weekly at Twitter. How often are these parameters being updated, clean, and retrained now? If any of this algorithmic filtering is live on the platform, censorship will still be in effect on Twitter. Since the n-gram technology used by Twitter was referred to by Musk as primitive, what new Machine Learning system & technology will Twitter replace this with to incorporate deep learning to prevent word filtering mistakes that often result in suspensions due to lack of context?
NO CLEAR LINE BETWEEN GOVERNMENT AGENCIES & BIG TECH AI. The CDC, government agencies, and academic researchers worked directly with Trust and Safety at Twitter to propose word lists to the Data Science team. This team was responsible for monitoring US political misinformation at Twitter. Should The CDC and government agencies have such a large role in the oversight and implementation of the algorithmic work of engineers and data scientists at Twitter? Data Scientists assumed that what they were told to do was accurate because it came directly from trusted experts. Are data scientists being put in a compromising position by government authorities?
A look inside the AI Domestic digital arms race fueled by NLP
Misinformation included real information.
Twitter flagged content as misinformation that was actually real information. Furthermore, their antiquated technology led to tons of false positives. The users suffered the consequences every time that happened.
99 percent of content takedowns start with machine learning
The story of deamplification on Twitter is largely misunderstood. It often focuses on esoteric terms like shadow banning or visibility filtering, but the most important discussion of deamplifcation is on word relationships that exist with NLP. This article reveals the specifics of how entity relationships between words are mapped to internal policy violations and algorithmic thresholds.
Every tweet is scored against that algorithmic system, which then leads to manual or algorithmic content review. The words you use can trigger a threshold in the system, without you ever knowing it. Only a tiny fraction of suspensions and bans actually have to do with the reason most people think. Part of this is because they have little knowledge or insight into the threshold, how it is triggered, which words trigger it, and what content policies are mapped to the alleged violation.
Censoring political opponents by proxy
If you want to censor a political opponent, NLP is the primary tool to use in the digital arms race. Largely still misunderstood by Congress and the media, Twitter was able to deploy NLP in plain sight without anyone noticing. One of the ways they were able to do this was through hiring third party contractors for the execution of the content moderation and data science work.
Therefore, when they told Congress they weren’t censoring political content that was right-leaning, they were technically not lying- because they used proxies to execute the orders.
Technically, the most important Twitter Files of all are not files that Twitter owns. The IP is scattered all over the world, and is in the hands of outsourced contractors in data science and manual content review. Who are these people and what are they doing with our data? Does anyone even know? No.
The term employee and contractor were used interchangeably when referring to this work. Contractors were used by Twitter as employees, but were not actually paid as employees, and were not given severance. That is a story for another investigation. But the part of this that people don’t understand is that the third-party agencies who hired those contractors to execute political censorship often had deep rooted political ties.
One of the third-party agencies Twitter worked with has a PAC, and frequently lobbies Congress for specific areas of interest pertaining to immigration. It is also worth noting that ICE was hard coded into the detection list, by one of the contractors the agency hired who frequently lobbies Congress for immigration reform.
So technically, Twitter is not doing it- the employee of the contractor is doing it. These are not neutral parties, and the contracting companies serve as proxies. Some of those companies essentially have shell corps, thus hiding the entire paper trail of the actual execution of the censorship.
If the feds ever decide to go knock down Twitter’s door to find evidence of political bias in their machine learning models, they won’t find it. Why? Because that evidence is scattered all over the world in the hands of third-party contractors- thus moving all liability on to those third parties, who did not even realize how they were being used as pawns in all of this until it was too late.
These were not people who went rogue or had nefarious intentions. They did not go off track. They did what they were told by the people who hired them and in alignment with the expert guidance of the academic researchers they trusted. They were not sitting there thinking about how to tip the political scales- but then again- they didn’t have to. They were told what to do and believed in the mission. This part is critical to understanding the full scope of the story.
The most important files won’t come from Twitter headquarters, they will come from contractors who had employment agreements with outsourced staffing agencies. Silicon Valley loves to disregard this poor behavior by saying this is how it’s done here. Well, maybe it should not be done that way anymore.
Their reckless regard for employment law has real world consequences. In an attempt to try to get away with not paying severance or benefits, the public ends up paying the real price for their arrogance because they are aiding and abetting the crime of free speech by making it infinitely harder for the government to track down evidence.
Twitter was complicit in a crime.
But the fact that they were complicit does not mean that they actually committed the crime. Instead, they used innocent parties (victims in my opinion) to commit the crimes for them. This is a clear and gross abuse of power at the highest level and a complete and reckless regard for the truth and system of justice.
The data shows clear evidence that Twitter deployed the AI to match the dialectic of only one way of talking about key political issues. The data also shows clear evidence that political misinformation does not exist in the dataset on the left. The entire category of political misinformation consisted of solely right-leaning terms. This is cause for concern and further congressional investigation.
At some point, Congress will be forced to compel further discovery to obtain the training manual used for Machine Learning at Twitter, which will contain the list of connected words and underlying vocabulary that tells the larger story of the dataset shared in this article. Those documents are critical to see the end-to-end process of how this was deployed.
Who creates the Machine Learning & AI tools used for active social media censorship?
Many of the tools are VC backed or funded with government grants under the guise of academic research. But the academic research is not subtle. The “suggestions” they make are actual policy enforcement disguised as recommendations. Make no mistake, these are not suggestions- they are decisions that have already been made.
I have said for years that whoever controls the algorithm controls the narrative. But we have reached a new part of this story- where it is on the verge of taking a very dangerous turn.
Whoever controls the model controls the narrative.
Ultimately, the one who can fine tune a model to their political preference will be able to tip the political scale in such a way that 99 percent of people will be oblivious to it- as evidenced by the publication of this article.
You could literally give the public everything they have ever asked for on a silver platter regarding the underlying technology that was deployed to censor political content on one of the largest social media platforms in the world- and yet- no one really cares. People don’t care about what they don’t understand. And that in itself is another issue with all of this.
The knowledge gap is growing wider by the day. Conservatives aren’t doing themselves any favors either by not even attempting to comprehend what is being said in this reporting.
This week, several former Twitter employees will take the stage for a congressional hearing. How many people leading that hearing will grill them on NLP? My guess? None.
What legal framework was used to deploy this system of social media censorship? Circumvention.
Third party agencies were essentially used to potentially violate the first amendment. How? Twitter used a corporate structure of outsourcing the most critically sensitive data science work – this enabled the company to get by without technically breaking the law. The corporation worked with several LLCs who then created the rules.
So, technically Twitter didn’t officially receive any instructions from the government. The LLC did. The same LLCs who were also tied to PACs and lobbied Congress. Twitter received the word list instructions from academic groups- who were funded with government grants. This story shows the deep corruption of Americas institutions at every level. Twitter used third parties to circumvent free speech laws. They were able to dismantle and censor free speech on the platform through natural language processing.
The intelligence community is working not only through academia, but also through shell corporations. All of this leads to a larger dystopian picture that big tech believes they are above reproach in society. That, fueled with the fact that VCs are also complicit in funding some of the censorship technology that is used to fight the very thing they claim to stand against- makes this story even worse.
The systems would degrade over time and nobody would ever know what they had done. The core systems used for visibility filtering to both train and manage machine learning models were often on the laptops of random third-party contractors that they alone had access to- but the company did not.
All of this has also been stated on record in an official whistleblower reporter.
My experience and first party reporting can confirm this to be true- which leads to serious data privacy concerns. It is not a Twitter employee that you should be worried about reading your data- rather- it is the thousands of contractors all over the world that still have this data that people need to be most concerned about.
EXCLUSIVE INTERVIEW WITH FORMER TWITTER EMPLOYEE ON AI/ML:
ML & AI: The most important levers of power and communication in The United States
DAU OR MAO?
Kristen Ruby, CEO of Ruby Media Group. interviewed a former Twitter employee on machine learning, artificial intelligence, content moderation and the future of Twitter.
What is the role of AI in mediating the modern social media landscape?
“People don’t really understand how AI/ML works. Social media is an outrage machine. It’s driven by clicks, and I think Twitter is/was vulnerable to this. On the one hand, when Trump was on the platform, he was all anyone could talk about. Love him or hate him, he drove engagement. On the other hand, Twitter was working to suppress a lot of what it saw as hate speech and misinformation, which could be seen by an outside party as bias.
Internally, we did not see this as bias. So much of social media is run by algorithms, and it is the ultimate arbitrator and mediator of speech. Public literacy focused on ML/AI must increase for people to understand what is really going on. There has to be a way to explain these ideas in a non-technical way. We all kind of get algorithmic and implicit bias at this point, but it’s a black box to non-technical people. So, you have people making wild assumptions about what old Twitter did instead of seeing the truth.”
How does Twitter use Machine Learning?
“In non-technical basic terms, Artificial Intelligence (AI) is the ability of a computer to emulate human thought and perform real-world tasks. Machine Learning (ML) is the technologies and algorithms that let systems identify patterns, make decisions, and improvements based on data. ML is a subsection of AI. The Twitter dataset that I have shared pertains to natural language processing, which is a form of AI.
I wish people would stop getting caught up in the semantic distinction between AI and ML. People seem to treat AI as a more advanced version of machine learning, when that’s not true. AI is the ability for machines to emulate human thinking. ML is the specific algorithm that accomplishes this. ML is a subset of AI. All machine learning is AI. AI is broader than Machine Learning.”
Can you share more about Twitter’s use of Natural Language Programming (NLP)?
“NLP is one of the most complicated processes in Machine Learning, second only to Computer Vision. Context is key. What is the intent? So, we generate features from a mixture of working with Trust and Safety and our own machine-learning processes. Using a technique called self-attention, we can help understand context. This helps generate these labels. We do in fact vectorize the tokens seen here. NLP splits sentences into tokens- in our case- words.
As stated above, the key in NLP is context. The difficulty is finding context in these short messages. A review or paper is much easier because there is much more data. So, how does it work? You have a large dataset you’ve already scored from 0-300. No misinformation to max misinformation.
Step 1: Split the tweet into n-grams (phrases of between 1 to whatever n is. In our case, usually 3 was max.
By this, I am referring to the number of words in the phrase you’re using. An n-gram could be 1 word, 2 words, or 3 words. There’s no real limit, but we set it at 3, due to the extremely small number of characters in a tweet.
Take that and measure accuracy. We searched for terms ourselves by seeing what new words or phrases were surfacing, and we also accepted inputs from outside groups to train our models.
Step 1. The tokenization and creation of n-grams.
Step 2. Remove stop words. These are commonly used words that don’t hold value -of, the, and, on, etc.
Step 3. Stemming, which removes suffixes like “ing,” “ly,” “s” by a simple rule-based approach. For example: “Entitling” or “Entitled” become “Entitl.” Not a grammatical word in English. Some NLP uses lemmatization, which checks a dictionary, we didn’t.
Step 4. Vectorization. In this step, we give each word a value based on how frequently it appears. We used a process called TF-IDF which counts the frequency of the n-gram in the tweet compared to how frequently it occurred across other tweets.
There is a lot of nuance here, but this is a basic outline. The tweet would be ranked with a score based on how much misinformation we calculated it had above.
When we trained our models, we would get a test dataset of pre-scored or ranked tweets and hide the score from the algorithm and have it try to classify them. We could see how good of a job they did and that was the accuracy – if they guessed a lot of them correctly.
We used both manual and auto. I don’t have the weights. That was calculated in vector analysis.”
What does the full process look like from start to finish?
“Here is what the cycle looks like:
We work with Trust and Safety to understand what terms to search for.
We build our ML models. This includes testing and training datasets of previously classified tweets we found to be violations. The models are built using NLP algorithms.
We break the words into n-grams, we lemmatize, we tokenize.
Then we deploy another model, for instance XG Boost or SVM to measure precision. We used precision because it’s an unbalanced dataset.
Then once we have a properly tuned model – we deploy through AWS SageMaker and track performance. The political misinfo tweets I showed you – the ones with specific tweets and the detections came out of me writing a program in a Jupiter notebook to test tweets we had already classified as violations according to our model score.
These models had all been run through SageMaker. Our score was from 150-300. The idea was that we were going to send these to human reviewers (we called them H COMP or agents) to help and tell us how they felt our model performed.”
Test or control?
“No. The misinfo tweets were already live. All of this was live.”
*The following screenshots will reveal the type of content Twitter was monitoring for political misinformation. The file included dates, language and annotation.
Pictured: “Detections show what we were looking for.”





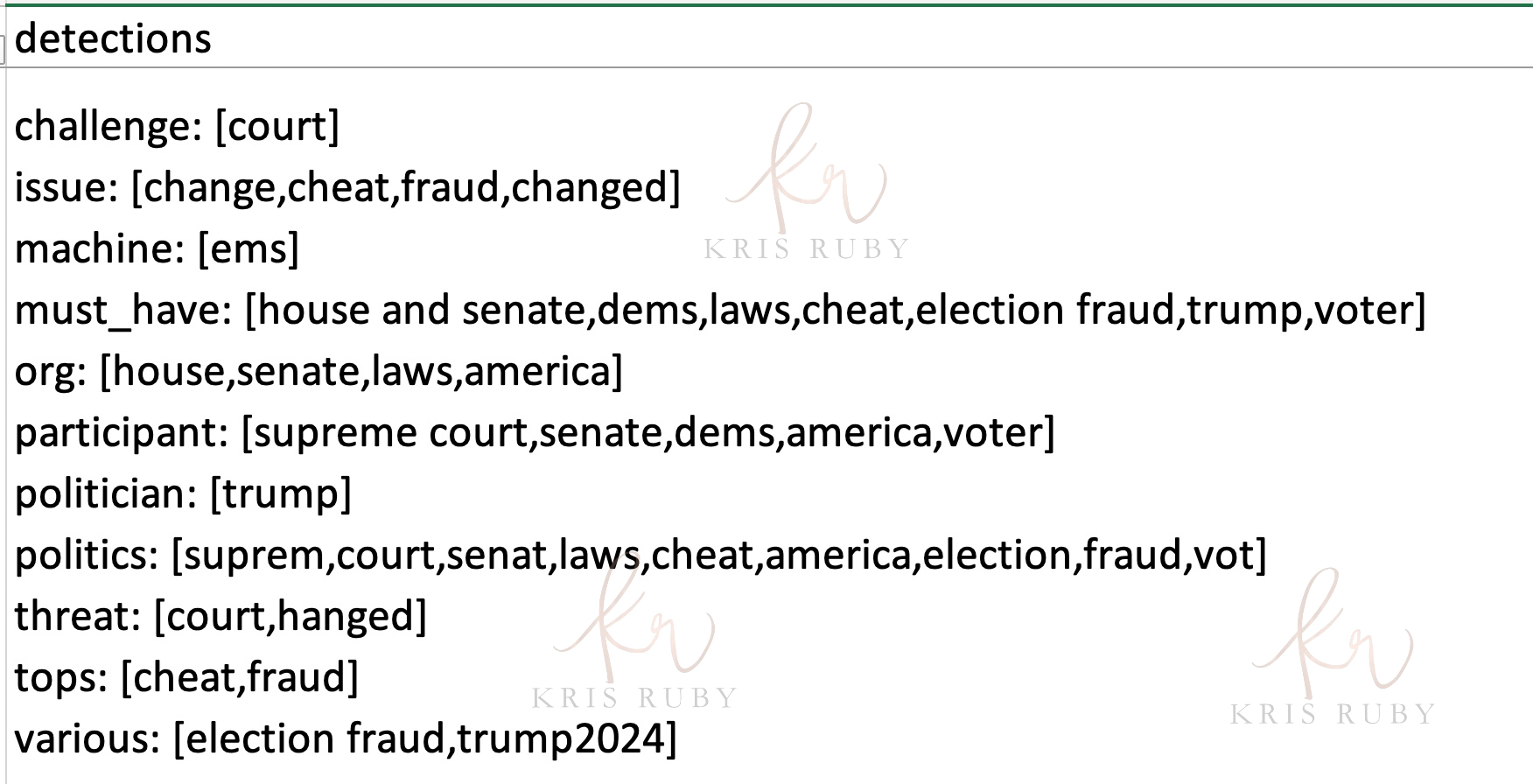


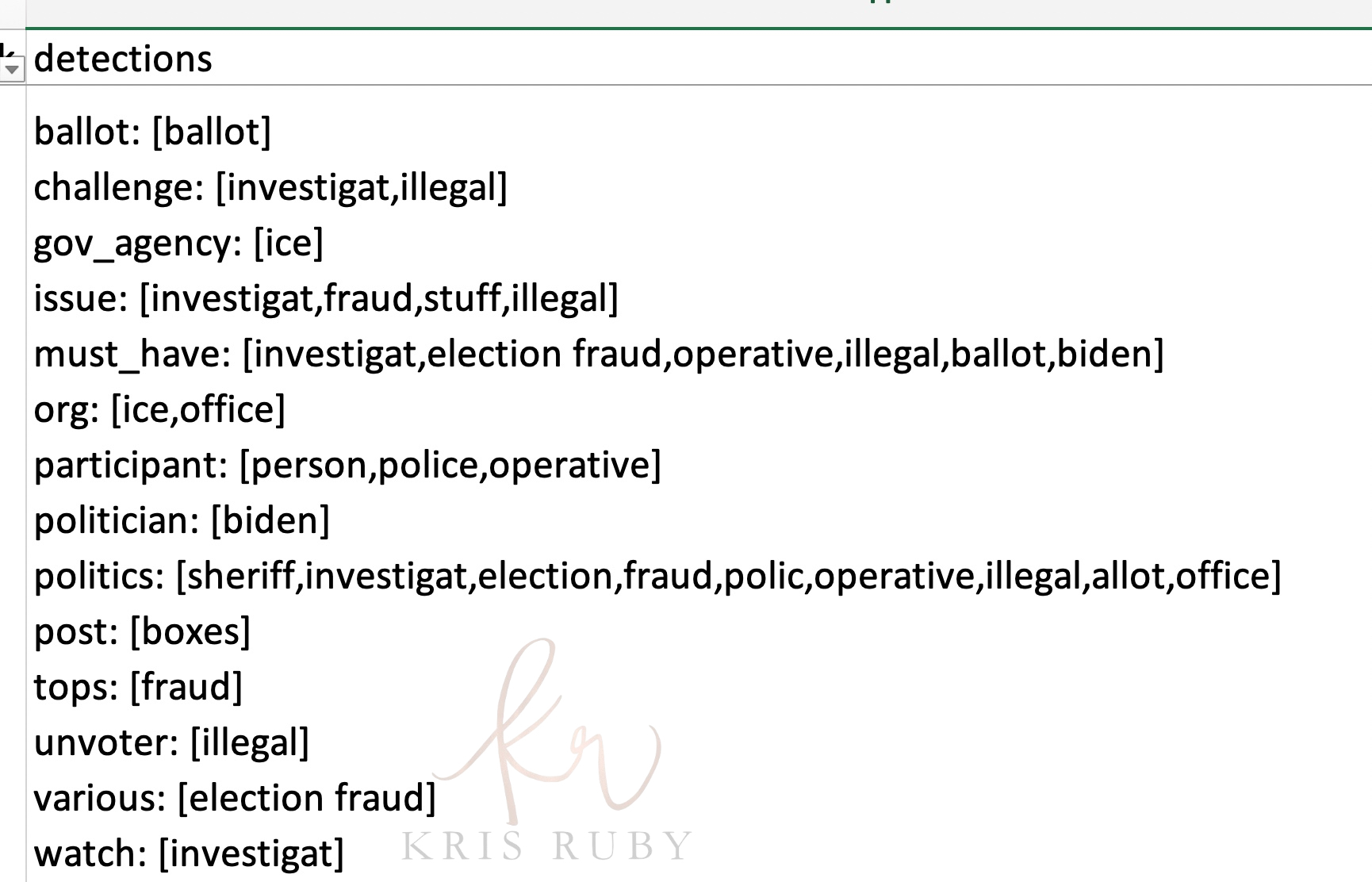



Caption: “We looked for terms. If there were enough of them your tweet could get flagged.”
What are we looking at? Is this a dump of rule inputs?
“Yes. This is one step in the process that shows just the inputs.”
Does this data show the full process?
“This dataset is only 1/10 of 1% of what’s going on here. The data shows you some of the things we were looking for at Twitter. I don’t claim this data is going to provide all the answers. It’s not- it provides only a partial view for only a few weeks in English, in U.S. politics. However, people may appreciate seeing information that is unfiltered. The public is subject to manipulation. This is data right from an algorithm. It’s messy and hard to understand.
Can you share more about the database access process at Twitter?
“I think it was a way to keep information segregated. To get access to a database, you had to submit a request. Requests were for LDAP access- just directory access. Once granted, you had access to all tables in that database. So maybe some of the engineering database or whatever had thousands of tables. But I built some of these and for highly specialized purposes. The schema would be like ‘Twitter-BQ-Political-Misinfo.’
It was fairly specialized- not for production so to speak. There were two layers of protection. The actions of the agents- human reviewers- were logged and periodically audited. Those are the people looking at those screenshots on PV2. That data went into a data table. It looks like a spreadsheet.
Access to that table was strictly limited in the following way. If you needed access for your job, you submitted a request. It needed to be signed off by several layers. However, once you had access, you had it. And that access wasn’t really monitored.
Here is how it worked:
We had some words and phrases we were looking for. These were developed in consultation with lots of people from government agencies, human rights groups, and academic researchers. But government itself can be a big source of misinformation, right? Our policy people, led by Yoel Roth, among others, helped figure out terms. But we weren’t banning outright.
Machine Learning is just statistics. It makes best guesses for unknown data (abuse, political misinformation) based on what it has seen before.
First, what did we annotate?
Here is a list of items we marked. It is global so I think interesting. The next file called political misinfo contains the actual tweets (only for the US election.) All of the tweets here were scored above 150, meaning they were likely misinformation. There is a field if a human reviewer decided if they were misinformation or not.”
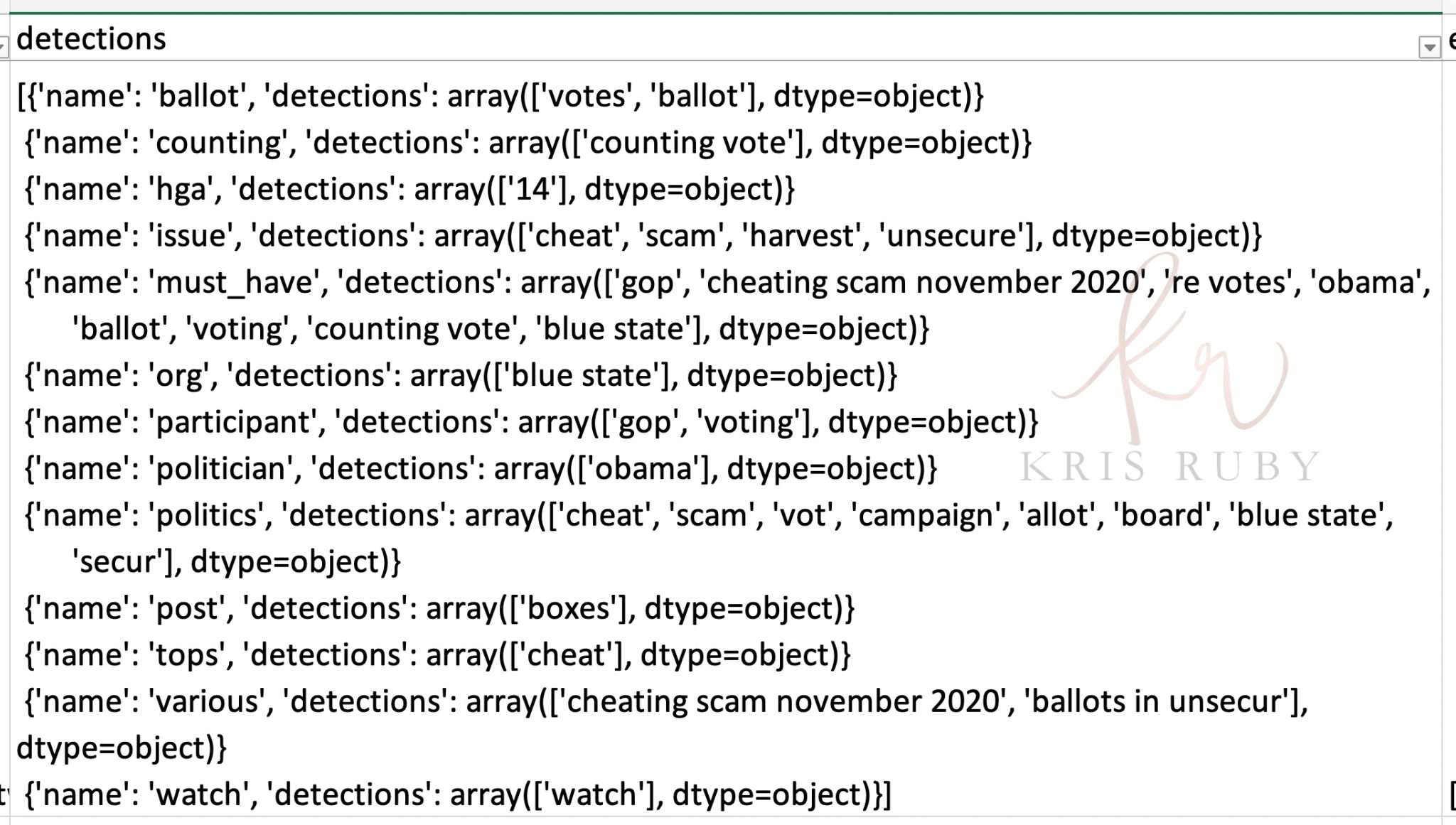
Examples of thousands of tweets marked for review that were flagged by Twitter as political misinformation:
Pictured: Sample results of the Machine Learning algorithm at Twitter in the US political information unit. When the ML scored 150 or higher, it was tagged as likely to be misinformation by Twitter.

Pictured: Sample of training data tweets deemed to be misinformation by Twitter.
*Please note, I have only shared a small sample of screenshots from the data I have.
TWITTER, AI, & POLITICIAL MISINFORMATION
What did the political misinfo team at Twitter focus on?
“We were most concerned with political misinformation. This included The US and Brazil. We focused on other countries as their elections came close.”
How did Twitter define political misinformation?
“Every tweet in this set was judged as likely political misinformation. Some tweets were banned and some were not. This dataset might show how Twitter viewed misinformation based on words and phrases we judged to be likely indicators of misinformation. For example, stolen election was something we looked for in detections. We aren’t searching for fair election tweets. Get out and vote type tweets.
We also searched for the movie 2000 Mules, which said that Democrats stole the election. Our opinion of this movie was neutral. We didn’t judge it, but what we’d found was that tweets which contained that term were frequently associated with misinformation. If you tweeted about that, stolen elections, and a few other things, our AI would notice.
We created a probability. We would give each tweet a ranking and a score from 0 to 300. The scale is completely arbitrary, but meant that tweets with higher scores were more likely to have misinformation.
MyPillow is in there because people tweet about it in conjunction with conspiracy theories. If you just tweeted MyPillow your tweet wouldn’t be flagged. Only in conjunction and context. It is important to look at the actual tweets we flagged. The clean text is the tweet itself.
We also needed a way to look at images, which is a whole other thing (that VIT flag you see).
A VIT flag shows up in the dataset with the actual tweets and the detections. Like “VIT removal”, “VIT annotation”. It was a way to look at images, which could interpret them for an algorithm.
Then we tried to measure context. What was the relationship in position to other words?
The list of words and phrases in the detection column are things we found in the tweet in that row. It’s not the whole picture. But the sample dataset gives a portion of the picture.
Regarding Russia/ Ukraine and war images, any images or videos suggesting the targeting of civilians, genocide, or the deliberate targeting of civilian infrastructure were banned. We had an image encoder, but there were some videos and images about some of the fighting that we flagged.”
Explain what political misinfo is.
“It’s a type of policy violation. It was originally formed in 2016 in response to the numerous fake news and memes generated during that election. The U.S. political misinfo was a data science division Twitter formed in 2016 to combat misinformation.”
Is all content related to political misinformation?
“No, the political_misinfo file is, but I worked on lots and lots of stuff. Other policies are sometimes shown. Political misinfo was my primary function, but I worked on many other things.”
What is the political misinfo jurisdiction? Is this limited to elections? What about Covid?
“We attempted to cover all issues related to politics. We focused more attention when elections were nearing, but could cover lots of non-election related issues. E.g. Mike Lindell and Dinesh D’Souza were talking about the stolen election well after the election was over. We still flagged discussion. We also flagged on images of war, or violence related to politics. Lots and lots of stuff. Also important to note- the U.S. midterms happened just as musk fired half of the company. People were fired Friday November 4th. Those of us left were working on the midterms for the next week until we were fired. I don’t think I downloaded anything that final week. The political misinfo file was the result of more frequent scanning during the run up to the midterm.”

Pictured: Misinfo tweets pertaining to US midterm election.
“These are daily tweets that the algorithm actioned that fell above the threshold of 150. As we get closer to the midterm election in The United States, you can see that from September- October 7, 2022, it trends upwards. The ML algo finds more misinformation as the days get closer to the election.”
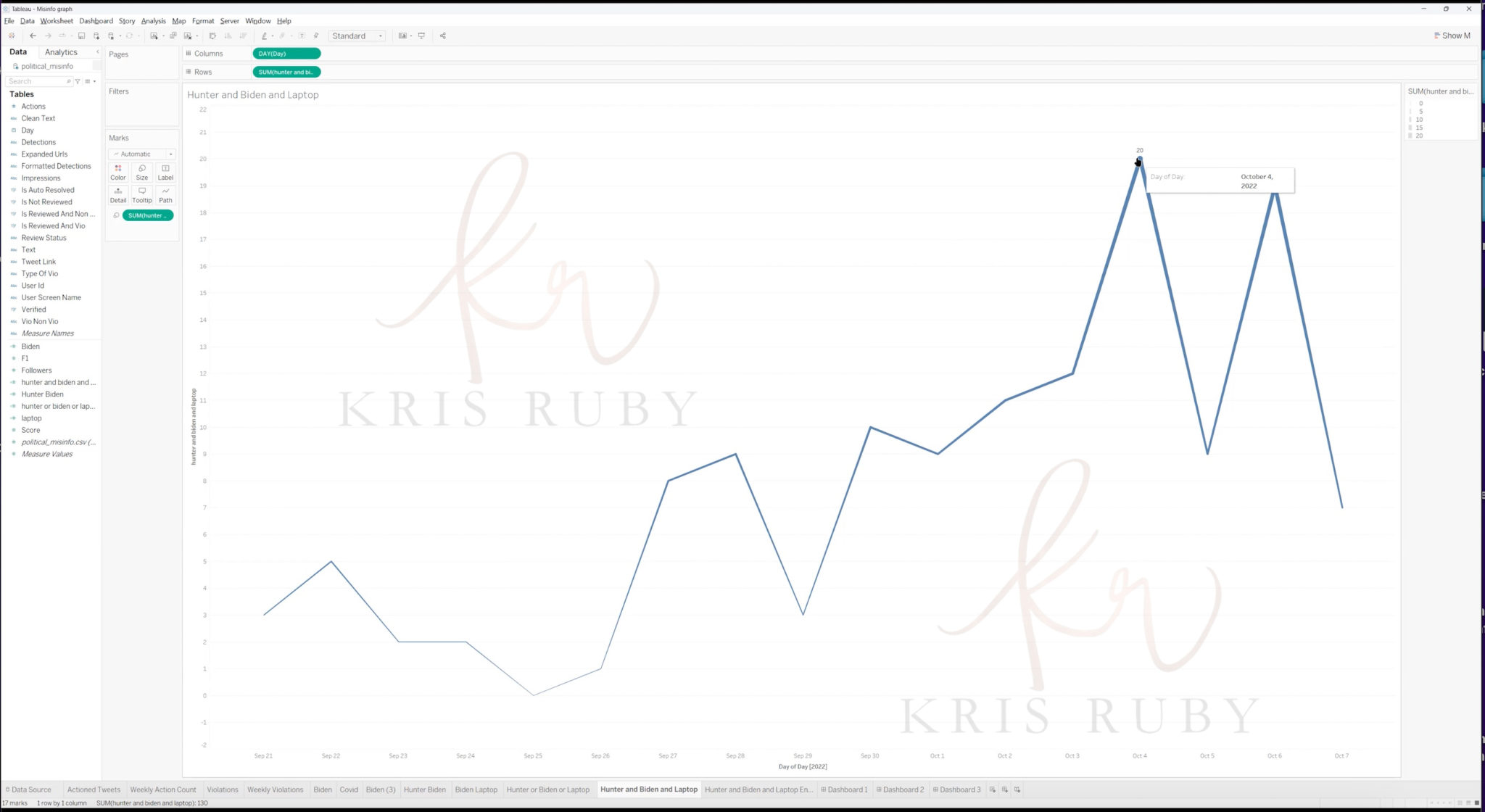
Pictured: Misinfo tweets pertaining to Hunter Biden laptop.
This image shows the number of tweets with the name Hunter and Biden with laptop in them that was caught a day during that time.’
Is the list of terms exhaustive?
“No, we covered elections all over the world. It was not exhaustive, just some we found.”
What is the date range of the data?
“Sept 13, 2021-Nov 12, 2022.”
Can you change or modify the input?
“You can have a log of the change. But very few people understand how it’s working. I had several dashboards that monitored how effective it was. By this I mean the accuracy and precision of the model. The only people who signed off on it were my boss and his boss before it was deployed and put into production. The health and safety team can’t understand the specifics of the model. They can say what they are looking for, but they don’t understand the specifics of the model. By they, I am referring to the team we worked with who helped us understand what ideas to search for.”
Please define N-Grams:
“N-grams include words or phrases we found in tweets which were violations (political misinformation). The us_non_vio_ngrams are the same – but no violation.
All words come from tweets judged to be:
- Political
- About the U.S. election process
We don’t have the tweets in this dataset, just words we found in tweets. This is similar to the ‘What did we action’ sheet I sent, but just words. That one was on policies which were violated. This is just the words or phrases, which led to the judgment.
Stop words are common words like ‘the’, ‘in’, ‘and’, judged to have no value to the model. They will not count in any calculations we make.
These are the things we are looking for:
(Shows me example on screen of data)
*This thread provides an inside look at the type of terms that were flagged by Twitter as political misinformation. Inclusion on the list does not mean action was taken on every piece of flagged content. Context is critical.
Building a proximity matrix. That’s what these machine learning algorithms do. You could just be saying this – but you want to judge it in context with other words. That’s the hard part. To look at them in context with other words and then to make a judgment.
(Shows me example of on-screen data)
‘Political misinformation is an even split. Despite headlines to the contrary. There is not a ton of political misinformation on Twitter. Maybe 9k per day on the busiest day when I was there.
Machine Learning was good at looking for it. The human work force could check for violations. Abuse, harassment, violent imagery- much more common- that is mainly machine learning, because there is so much of it.
All ngrams in the detections list show words or phrases being violated. Important to understand these were made in context. We tracked hundreds of n-grams.”
Twitter N Gram examples:
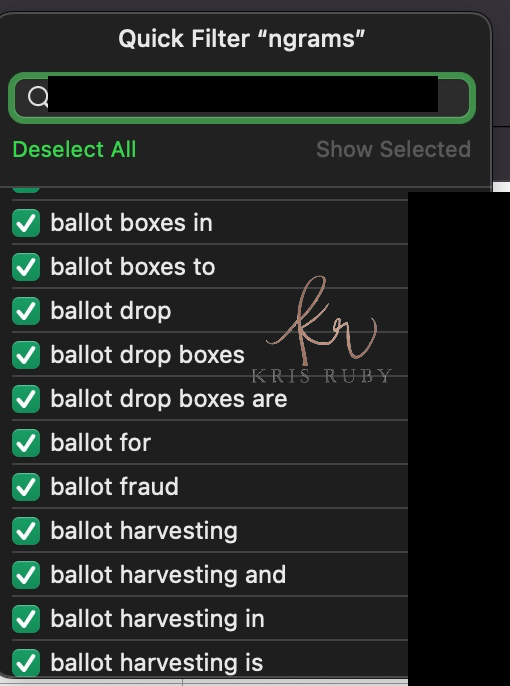
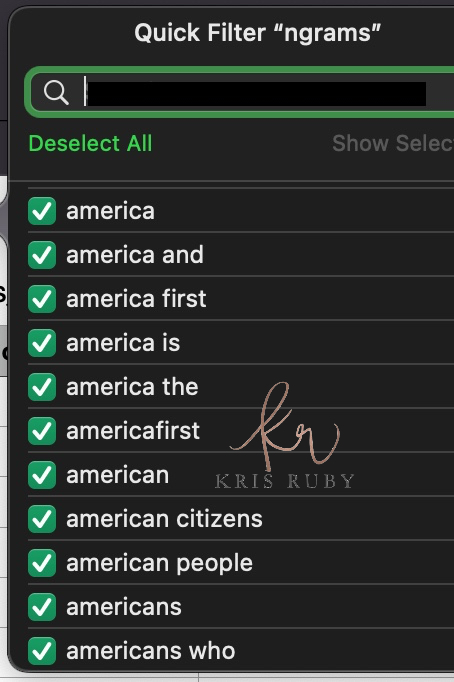

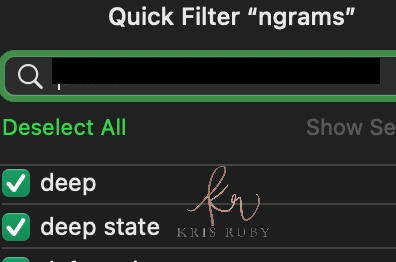

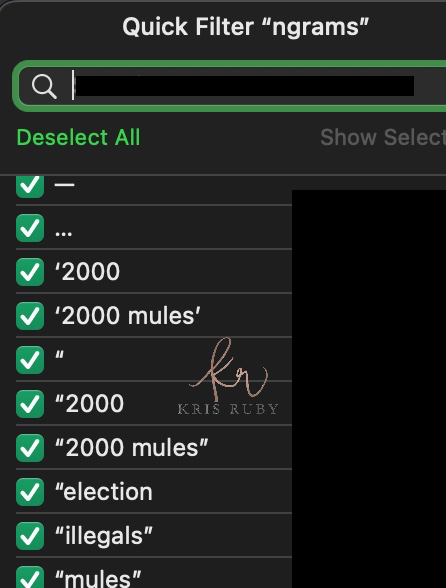
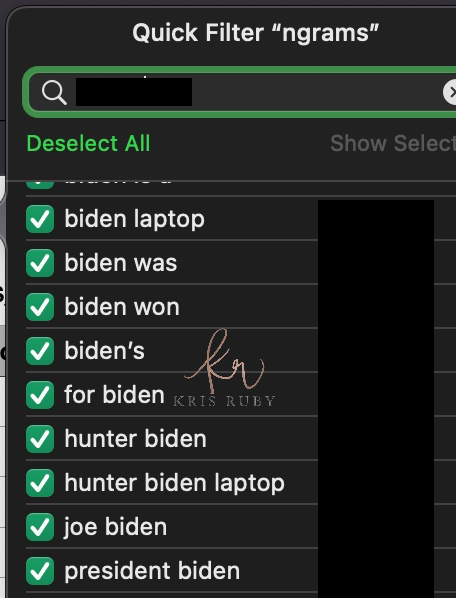
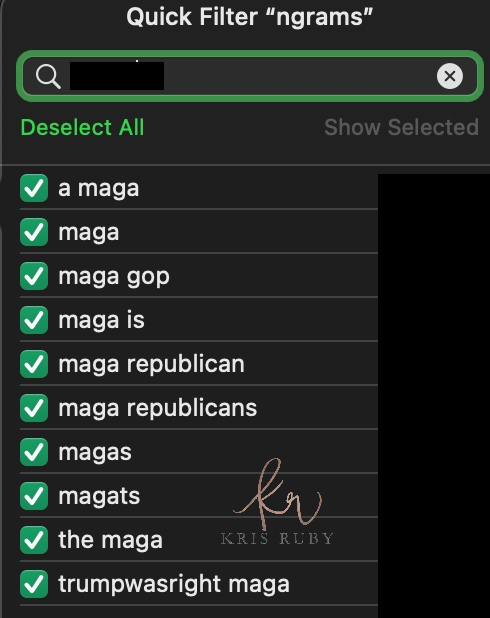

💎A few more Twitter N-grams for you: #RubyFiles pic.twitter.com/RgjUshonEI
— Kristen Ruby (@sparklingruby) January 27, 2023
Natural Language Processing and Social Media Content Moderation
What is the big picture?
“We aren’t searching for fair election tweets- get out and vote type tweets. This list gives you a look into the types of content we determined to be political misinformation.”
The political_misinfo file I sent has actual tweets we flagged. We scored these at or above our minimum level for misinfo. These specific tweets are shown with the words or phrases which were used to classify it that way. These were sent to human review so they could give us feedback on whether or not they considered it misinfo. In other words, did our algorithm do a good job? Other files show specific policies violated and how many times or when they were violated.”
What does the data show?
“These tweets are tweets that we considered violations of our political misinformation policy. They may or may not have been reversed later. You can assume we felt these tweets were dangerous politically. That’s why they were banned. The list of policy violations shows general policies we were looking for at Twitter.”
Why is Letitia James flagged?
“Letitia James was there because many people had theories about her and aspersions on her character. People said nasty stuff and she was also part of conspiracy theories.”
Why is a photo of a Nazi saluting a flag in Ukraine dangerous enough to ban?
“Because it was being used as a justification for war and it was a lie.”
I see the word deep state. Why?
“Deep state was definitely there. It’s one of those things we judged as a keyword to indicate a conspiracy theory. However, it is important to note that word alone wouldn’t get you banned. But in conjunction with other terms, we felt it was a likely indicator. I do see that it lends to the perception of left-wing bias. Keywords are a part of NLP. The context to which the tweet is referring to is important.”
What does the Greta line refer to in the data?
“Greta trash ID refers to a photo of her circulating that claimed the climate rally events she attended had a lot of trash at them. It was an attempt to discredit her and we considered it slander. The photo was similar to this one – without the fact check sticker on it.”
What does the Brazilian protest line refer to in the data?
“The Brazilian protest videos were related to Covid. The claim was they were protests against pharma companies.”
Why was the American flag emoji on the n-gram list?
“The flag emoji, and particularly multiples were just one thing we looked for. Please keep in mind none of these are prohibited terms. We’d found them to be likely to be associated with misinformation. For sure it can seem like bias. Sorry. I know it looks like bias. I guess it was.”
What is the Rebekah Jones annotation?
“Rebekah Jones was the subject of a smear campaign and violent threats due to her involvement in Florida Covid tracking. Later she ran for Congress and all of the hate just came back up again.”
Why were certain things flagged in the data? Misc. answers on flagging:
“There were many conspiracy theories that China or the FBI were involved to help Biden.”
“It contained allegations of specific crimes. In our view, those allegations were false. We felt we had a duty to stop the spread of misinformation.”
TWITTER & NATURAL LANGUAGE PROCESSING
Why are certain phrases misspelled?
“NLP uses something called stemming. Ran, run, running are all verb tenses of the same word. NLP tries to figure out the stem of a word and only uses that. Sometimes it uses a shorter version ‘tak’ for take, taken or taking.”
Please share more about the technology used at Twitter:
“We used a variety of approaches. Python is the language we used. So NLTK, Vision Training, various natural language processing algorithms. We were using a variety of NLP models. Nobody else is using anything that is more advanced. I have visibility into what Meta is using. We used a lot of NLP and computer vision.
In terms of the database used, we interacted with data through a tool called BigQuery, an SQL interpreter (SQL stands for structured query language). It puts data into tables similar to excel spreadsheets. It pulls from a SQL database. What is it pulling? The text of the tweet. There was a table called unhydrated-flat. That table held tweets as they came in. This Python code pulled from that table.
We also used AWS to host data and deploy our models to production. AWS can interact with data in Python or JavaScript to build out data tables. In my case, the data was developed in Python and hosted through AWS.
I used many tools including Support Vector Machine (SVM), Naive Bayes. Google’s Jigsaw Perspective was used for sentiment analysis.”
What is the difference between supervised and unsupervised learning?
“AI is a series of probabilities. Supervised learning is where you ‘know’ the answer. For example, let’s assume there are 10,000 people in your dataset. Some have diabetes, some don’t. You want to see what factors predict diabetes. Unsupervised – you don’t know the answer. You feed the algorithm 1,000,000 photos of cats and dogs but don’t tell it what it’s looking at. You then see how good it is at sorting them into piles. Unsupervised learning is often an initial step before supervised learning begins. Not always, but sometimes.”
Did Twitter use supervised or unsupervised learning?
“We used both. NLP can be done either way. I happened to use supervised learning, but you can use either. Each has advantages. The point is to have lots of models running to see which works best. Largely because of the complexity of the data, no one approach is best. Not all of the models were unsupervised. Our supervised models were used in different ways. It’s an incredibly complex thing with many moving parts.
Our unsupervised model:
We were scoring based on context, so not just ‘deep state,’ but that ngram and ‘stolen election’ combined with others in a certain order and with other likely indicators such as size of following, follower count, impressions.
For our unsupervised model- we used both skip-gram and continuous bag of words (CBOW). The idea being to create vector representations. This helps solve context issues in supervised learning models such as the ones I’ve described. The embeddings help establish a representation in multi-dimensional space. So, the human mind can’t visualize beyond 3D space, but a computer can. No problem.
A classic example here – we would associate king with man and queen with woman as seen in the diagram. In short, CBOW often trains fast than skip gram and has better accuracy with frequent words. But we used both. Now, here’s the thing. Both these models are unsupervised BUT internally use a supervised learning system.
Both CBOW and skip-gram are deep learning models. CBOW takes inputs and tries to predict targets. Skip gram takes a word or phrase and attempts to predict multiple words from that single word.
Skip-Gram uses both positive and negative input samples. Both CBOW and skip grams are very useful at understanding context.
We factored our words into vectors using a global bag of words model. The NN models we used were the unsupervised ones that used embedding layers and GloVe. We felt a varied approach and using many different models produced the best results.
We used it on unsupervised models mostly. Or GloVe. But Word2Vec is better for context training. The data I showed you was on supervised models, which don’t use any word embeddings to vectorize such as Word2Vec.
To calculate multimodal tweet scores, we used self-attention, so that images or text, are masked. Our model used self-attention to compute the contextual importance of each element of the sample tweet, and then attempted to predict the content of the masked element.”
TWITTER MACHINE LEARNING (ML) MODELS & BOTS
How often was the model updated?
“It was updated and retrained weekly near an election and monthly otherwise.”
How many bots are used at any given time?
“There are multiple bots running in the background all the time.”
Shows me an example of a flagged tweet on screen:
“I used Python to find this. I wrote the script.
Trust and Safety helped us to understand the issues. I deployed it. We used AWS SageMaker to put ours into production. There are lots of bots all the time and we are always ranking them against each other to see who was doing a better job. They are not very good. They have a 41 percent rate of success.
There are two ways you can get it wrong.
- False positive – you say something is misinformation and it’s not.
- False negative- where you say something is safe and it is misinformation, abuse, or harassment.
If you feel these things are not legitimate, then you feel that there is bias.
These are what we made a decision on.”
How did AI detect bots on Twitter?
“Sometimes the AI data would show who is a bot. It’s hard to find out who is a bot. If you tweet a bunch in a short period of time that can be a signal. It’s been a continuing issue at Twitter that we never fully solved. There definitely are bots on the platform but they are notoriously difficult to detect. Easy to deploy. Difficult to detect.
It is a tough problem to root out bots. That’s why we had such a difficult time. It’s hard to really know what’s a bot and what is not because they can be created so rapidly. Musk himself acknowledged this too.”
You stated there were two different types of bots on Twitter. What is the difference between both types?
“We wrote scripts – known as bots – autonomous programs that performed some task. In our case, the bot was looking for political misinformation tweets. Bots can also be fake or spam accounts. It is still the same idea – an autonomous program that performs an action – in this case searching for info, or trying to post links to malware, etc.”
Were different algorithms involved?
“Yes. For example, that is a different algorithm that affected the home timeline. To the extent that they would affect them is if your tweet was flagged by an algorithm that a data scientist wrote and kept off the general home timeline would still show up for the timeline of the person’s followers.
The U.S. bot tweet file shows things flagged by our bots or algorithms.”
TWITTER TESTING & MACHINE LEARNING EXPLAINED:
Please explain what testing means in the context of AI/ML:
“Testing is when you have a machine learning algorithm and want to test to see how good of a job it did. The relationship between training and test data is that training data is used to build the model. Test data checks how good the model is. All data is preserved. When new data comes in (new tweets), we test our model on that data. That is why it is called machine learning. It learns from new data. In machine learning, we have a dataset. Let’s say we have a dataset of two million tweets. I split that data into a training and testing dataset.
Let’s say 80% training and 20% testing. I train my model on the training dataset. When that training has occurred, I have a model. I test that model, which is a ML algorithm, on the test dataset. How good a job did the model do at predicting with actual data? If it is very bad or doesn’t get many correct, I either try a different model, or I change my existing model to try to make it better.
Machine learning models ‘learn’ by being trained on data. Here are one million tweets that are not violations- here are some that are. Then you have it guess. Is this tweet a violation? If it guesses it is a violation, and it is, that is a true positive. If it guesses it is a violation and it isn’t, that is a false positive. If it guesses it is not a violation and it is, that is a true negative. If if guesses it’s not a violation and it is, that is a false negative. The idea is to get the true positive and negative up and the false positive and negative down. New data helps with that.
If your tweet scores high enough, above 150, our algorithm could ban, annotate, or suspend the account, but we tried to be selective. In the tweets I sent over, not all that scored very highly ended up being banned.”
I predict Twitter Spaces data could be used to train a model.
“Yeah. Definitely. Anything on the site is fair game. We used everything to train.”
ML EXPERIMENTS
What is in the machine learning database experiment list?
“Those were all of the experiments we were running in our A/B test tool. The one where we ran our suspension banner experiments. The tool was called Duck Duck Goose.
Whenever I pulled data from this table, I always filtered it to just my experiment data.We started in December and ours ran for nearly a year.I probably ran a query to give me a unique list of names of all experiments in the table. I think I noticed some crazy names and was like ‘what is this?’
This is also many years of data. I intended to investigate at some point. That’s probably why I downloaded it. But you know how it is. You get busy with other stuff. It is always easy to say ‘I’ll look into that later’.”
🔬 We are all lab 🐀 in a giant social experiment 🧪#SocialMedia #Twitter pic.twitter.com/PIvBBfN0QO
— Kristen Ruby (@sparklingruby) January 11, 2023
Did these experiments run? Were they live?
“Do I think they ran? Yes. They wouldn’t be in the table if they hadn’t run.”
Is visibility filtering ever positive?
“It’s usually a content moderation tool. I can’t think of any other use. I just don’t know the context here re what was being filtered and why.
In an A/B test, you are testing how people will react to a change. You randomly assign a group into either an A group or a B group (in our case test and control instead of A and B). Then you show one of them the change and do not show it to the other group so you can test how people react to the change.
The numbers attached to the end are catalogue numbers. We had to assign some unique id to track. I think that’s what they are.
Lots of groups use A/B tests. They are beloved by marketing and sales for instance. Those are names of tests. A holdback is a group that will never be exposed to the test condition.
You have a source of truth for how people react. It’s usually quite small. 1% in our case. This was not limited to data science. That’s why I have so little visibility.
Is machine learning testing ever used for nefarious purposes?
“Yes. Testing can be used for nefarious purposes.”
What is the process for gaining access to run an experiment?
1) You need to apply for permission.
2) Once permission is granted, you need to apply to run your experiment. They took it pretty seriously. You’d need to fill out a formal application with the scope and written statement proving a business case.
3) It was moderately technical to set up. Not like PhD level, but you would definitely need to have help or take your time to figure it out.
4) Once it ran, you didn’t have to touch base except to increase or decrease the sample size or to end the experiment.
TWITTER, CONTENT MODERATION, & AI
Discuss the content moderation process at Twitter and the role of AI in it:
“If you got a high score and we marked you- we might just suspend you. We might just put you in read-only status, meaning you can read your timeline, but you can’t reply or interact. Read-only was a temporary suspension.14 days typically triggered to a certain tweet. That is different from permanent suspension, which could include violent imagery.
Direct threats of violence would be triggers for immediate banning. Abuse was our largest category of violations. There were hundreds of models running all the time.
In terms of work on the appeals process- users were complaining that they didn’t even know what tweet they were banned for and that was a problem. We worked hard to identify the tweets so they would know.
AI can set a flag on a tweet and perform an action automatically. If it was later determined that the flag was set unfairly or incorrectly it could be removed, but I don’t know if that was done by AI. AI was flagging tweets for suspension. Removals had to be done by appealing or second pass. The AI went through with second pass. You could appeal and it would be seen by a human. You could appeal and it would be seen by AI. If you were seen by AI the flag could be removed.
AI would evaluate it. If you appealed your suspension and another model evaluated your tweet, it could remove your suspension. AKA, if it appealed -the second model not the model that logged you. A different model. If it determined with a high degree- in the second round -higher degree of accuracy that the tweet was in violation- we might uphold the appeal. If it was not sure at the high level, then you might get sent to human review. Also, your appeal may go to human review instead of another model.
It sounds dystopian. Part of the reason we did that was the sheer volume of what we had to deal with.
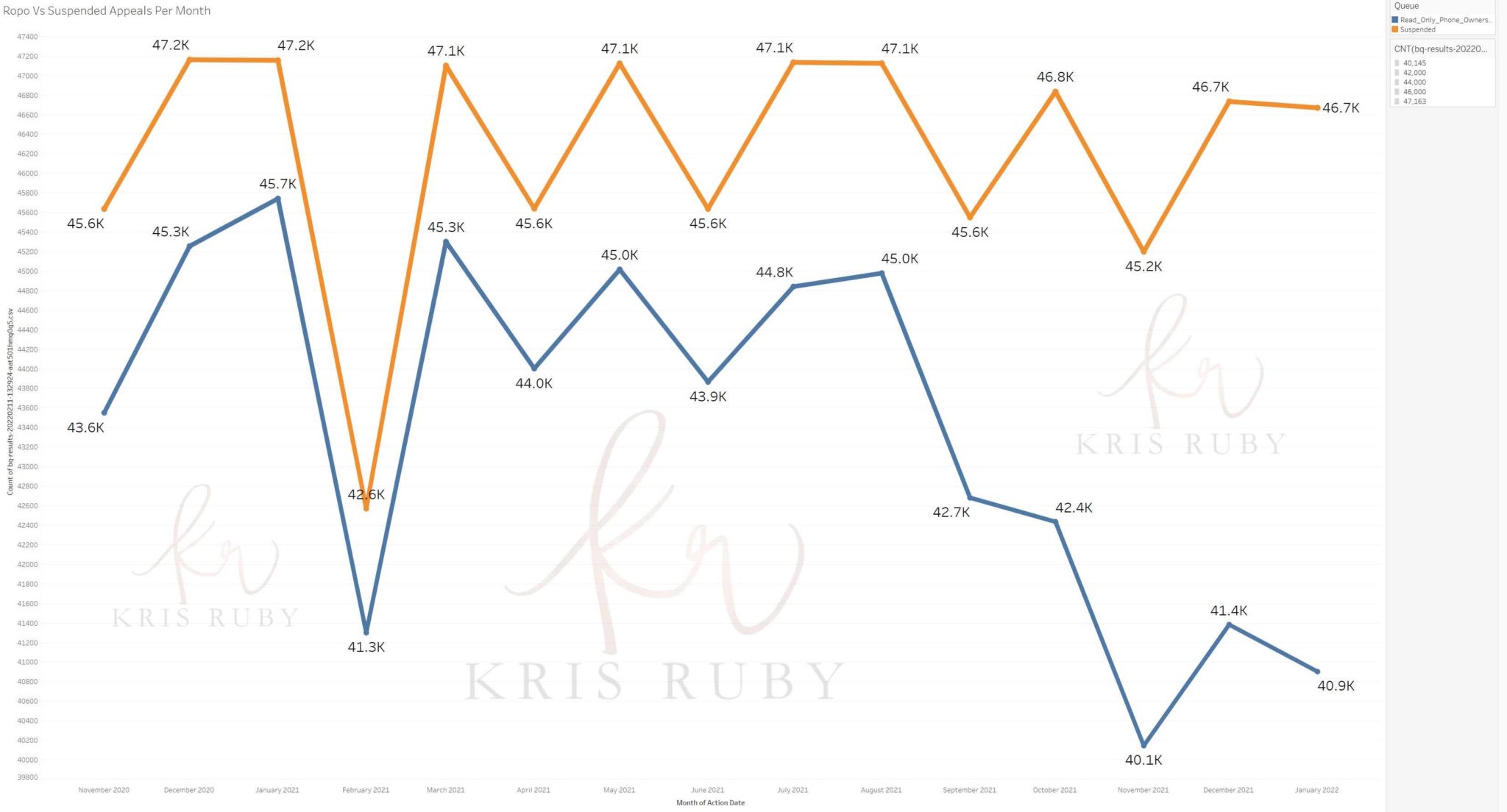
Here is a screenshot comparing the number of appeals per month between permanent suspensions (i.e. you are banned entirely) and read-only phone suspension or ROPO, when you are temporarily blocked for a max of 14 days, or until you perform an action such as deleting the offending tweet.”
What is an action?
“An action is any of the following:
- Annotate
- Bounce
- Interstitial
They are all actions. Bounce is suspended. Annotate and interstitial are notes we made for ourselves to resolve later.
This data is related to an appeals project I worked on. Previously when a user was suspended, they wouldn’t even know they were until they tried to perform an action (like, retweet, or post) and they would be prohibited.
We built a suspension banner that told users immediately that they were suspended, how to fix it, and how long they would be in suspension. These files are all related to that. We wanted to see if that banner led to more people appealing their suspensions (it did), because that might mean we had to put more agents (human reviewers) on the job because of increased workflow.
The data is all aggregated with daily counts, time to appeal, etc.
We were trying to roll out a test product enhancement that would show users who had been suspended a banner that contained information on the suspension.
For this specific ML experiment, we used test and control groups so that we could see if users shown the banner had different behaviors.
- Did it take them longer or shorter to appeal?
- Did it cause them to appeal more frequently?
Users in the test column were shown the banner and those in control were not.
Column E is time to appeal. I was trying to calculate if they were appealing faster with that banner.
The banner was a little rectangle at the top of the screen that couldn’t be dismissed. It would show:
- Your suspension status
- Time remaining in suspension if not permanent
- Links to appeal and information about where you were in the process
The control group was not shown a banner.
So, the end of this test was that it increased the appeal rate – users were more likely to appeal – this had effects on human reviewers downstream who might have a bigger workload if more people appealed. Also, time to appeal was reduced. People appealed faster which makes sense. They did appeal faster and were more likely to appeal if they saw a banner.”
What is the takeaway in this dataset for non-technical people?
“I think the takeaway from this dataset is the extremely high number of appeals daily. Remember, there are about 500 million tweets every day and that number of appeals suggests people were not happy, thought the ban was wrong, etc.
The second takeaway is appeals for permanent suspensions (what we just called suspensions) are way higher than bans for temporary ones (we called read-only phone ownership).
This makes sense, because you may be more likely to appeal if you’re permanently banned than if you’re only locked out for a bit.
I don’t have the overturn rate, but it was fairly high as well. Meaning, your ban was overturned on appeal.
The time to appeal (TTA) metric was an attempt to calculate time to appeal. This was part of the in-app appeals project, which would make the entire appeals process easier and more transparent.
We were trying to measure time to appeal because we wanted to get a sense of the effect this new process would have on total appeals, time to appeal, etc. The idea is, if more people are appealing, more agents should be allocated to review those appeals.”
What is guano?
“Every database serves a purpose. Tracking actions or tweets we had probably hundreds if not thousands of databases each with several tables. The raw data existed in a guano table in each (most) databases. This was called guano because they had dirty non-formatted data. You could also make notes in them. If a tweet was actioned it means we marked it in some way, it would have a guano entry. Sometimes we would take notes on a tweet and those tweets would be collected in a guano table.”
TWITTER DIRECT MESSAGE ACCESS:
Could employees read Twitter users DM’s (in your division)?
“Yes. We could read them because they were frequent sources of abuse or threats. Strict protocols, but yeah. So, if I am being harassed I might report that so Twitter can take action.”
What protocol was in place for access to confidential user data and Direct Messages?
“We dealt with privacy by trying to restrict access to need to know. As far as bans, the trends blacklist indicates it on a list of trends blacklisted- meaning it violated one of our policies. The note up top is interesting. We couldn’t take action on accounts with over ten thousand followers. That had to be raised.”
Did you have access to private users Direct Messages?
“Yes. We had access to tweets. That is how we trained our models. We would make a tweet as misinformation (or not) or abuse or whatever like copyright infringement. People who had access were pretty strictly controlled and you had to sign off to get access but a fair amount of people working in Trust and Safety did have it.”
SHADOW BANNING & VISIBILITY FILTERING ON TWITTER:
Did Twitter engage in shadow banning?
“I don’t mean to sound duplicitous, but let’s first define shadow banning. Twitter considered shadow banning to be where the account is still active, but the tweets are not able to be seen. The user is literally posting into thin air.
Here is what we did. We had terms which, yes, were not publicly available, along the lines of hate speech, misinfo, etc. If your account repeatedly violated this but we decided not to ban you- maybe you were a big account, whatever- we could deamplify. That is what I mean by corporate speech seeming shady. So, your tweet and account were still available to your followers. They could still see, but the tweets were hidden from search and discovery.
We tried to be public about it. Here is a blog post from Twitter titled ‘setting the record straight on shadow banning.’ Not a perfect system. You could argue, reasonably, I think, that this is shadow banning. But that’s why we said we didn’t.”
Were you aware that users were publicly banned from searchers? How much if this was shared with employees vs. limited to certain employees?
“Me? No. I didn’t know. Those screenshots are from a tool called Profile Viewer 2 (PV2). If it is data that is captured, as this data was, someone could see it and was aware, but not me. Those are tools for people we called agents – people who manually banned tweets or accounts. I was definitely an individual contributor and didn’t have the full picture.”
Was shadow banning and search blacklisting information shared with other teams?
“No. Heavily siloed data. I literally just counted violations to see how good our algorithms were performing. That is part of content moderation, technically called H Comp. So, they were aware of it, but not me. Few employees were aware. Managers in the thread of former data scientists are like, what?
There is a disconnect between what Twitter considers censorship and what others in public consider censorship. Twitter feels it was very public about what it was doing, but this was often buried in blog posts.”
Source: Twitter blog titled “Debunking Twitter Myths”
POLITICAL MISINFORMATION, TWITTER, & AI:
What outside groups provided input on words and phrases deemed political misinformation?
“Typically, governments, outside researchers and academics and various non-profits could submit words. We didn’t have to take any of them, but I’m sure we took requests from US government agencies more seriously.”
What are some examples of outside groups you worked with or that provided input?
- CDC
- Academic Researchers
- Center for Countering Digital Hate
- FBI
- Law Enforcement
There were others. I don’t know all of them.”
Who are the key players involved in content moderation and who did you collaborate with both internally and externally?
- “Trust and Safety. We worked with policy and strategy, people who were experts in their country to understand the laws, customs, and regulations of the country. We got information from the government researchers and academics. This helped us formulate policy not just in the US, but around the world.
- Data scientists writing machine learning algorithms.
- Human reviewers.”
Who created the Machine Learning (ML) dataset at Twitter?
“We worked heavily with Trust and Safety. Machine learning works on probability. We said if there are that many things I am seeing in cell h9 -ballot detections- these are all the things we found in this tweet- that’s what makes it have this score of 290.
I wrote the scripts. Trust and Safety helped us to understand the issues. I deployed it and put it into production. Data scientists write the algorithms. Trust and Safety regularly meets with a data science department dedicated to political misinfo.
Who was responsible for deciding what was deemed misinformation? Who told you the model should be trained on those parameters?
“Trust and Safety mainly. We worked with Trust and Safety, who provided many of the inputs. Algorithmic bias is real. Machine learning reflects those biases. If you tell a machine learning algorithm that tweets which mention the movie 2000 Mules are more likely to contain misinfo, that is what it will return.
We met regularly with Trust and Safety.
They would say, ‘We’d like to know X.’ How many vios on a certain topic in a certain region? We could help generate dashboards (graphs all in one place) for them. Then, they could also help us understand what terms to look for and it was all part of our process.
We worked within the systems to build our models so they would conform to the policies and procedures laid out by Trust and Safety. They were policy experts. They understood the issues. We were ML experts. We knew how to code. That’s how it worked.
Also, the strategy and politics and health and safety teams were involved. We are in meetings with them. They say, these are the things we are finding. We then write algorithms based on that. How good of a job does this do? We also worked with human reviewers to make our algorithms better. Other people helped to set the policy. I am not an expert at elections that I worked on. That is why we had to have these people to help us understand the issues.
The terms were created by working with the Trust and Safety- who were the experts. Also, by working with the government, human rights groups, and with academic researchers. That is how we got wind of these terms.
On the question of if we were looking for conservative specifically- the terms we looked for included stolen election, big lie, Covid vaccine, etc. That is what we looked for.”
You worked with the US government?
“I mean like- yeah. We definitely worked with various government agencies. Did we take requests from The Biden White House? I don’t have any knowledge of that. I do know we worked with certain government agencies who would say these were things they were seeing that were troublesome to them. We worked with government agencies around the world. We had to make internal decisions as to what was a legitimate request and what was not. We got the terms from Trust and Safety.”
TWITTER, AI, & CONTENT MODERATION PROCESS:
Describe the content moderation process at Twitter and how AI was involved:
“Agents or human reviewers could get wind of a tweet through somebody reporting it. The tweet had to reach a certain critical mass of people. If enough people reported a tweet in a short enough time, then it would come up for human review. It had to be reported by enough people then a human could review the specific tweet and make a decision based upon what they felt.
My algorithms were patrolling Twitter and trying to find violations specifically in political misinformation.
(Showed me via video example of tweets that violated misinformation policies around politics).
This is not a complete list of everything we looked for- just the terms found in a specific tweet. It’s not the whole picture, but a small slice of data opens a window into a subset of it.
You could be banned by the algorithm. You could be banned by the person.
By far, the algorithm was banning a higher number because there are just so many tweets. There are multiple bots running all the time.”
How many people signed off on this?
“I would develop the model. The only people who really signed off on it were my boss and their boss before it was deployed into production. The health and safety team can’t understand the specifics of the model, but we can say this is what we are looking for based upon what you’ve told us. They can say that sounds great and then we can show them what we have found and they can say that looks good. As far as the specifics of the model, they don’t understand it. There are only a few people trained to work on this. Very few people understand how it works. I had several dashboards monitoring how effective it was. If we suddenly saw a drop, somebody might take notice. We reported the results out. The system is pretty fragile in that way. We were aware of the inputs. I never thought of myself as choosing them.”
Is there is a misconception that humans are more involved in content moderation decisions than they really are?
“Yes, it’s an incredibly complex system with many competing ideas and models and it’s always evolving. If you check back with me in a year, all of this may have been replaced with something new. The application involves complex math – graduate-level statistics, calculus, etc. To implement a model, you also need a deep knowledge of coding and the ability to put your model into production. It’s very complex and many people are involved. I think people don’t really know how much these algorithms run the Internet, not just content moderation. They are responsible for much of what we see online.”
vIT is a tool we used for vision information technology. Vision transformers- ways of scanning -was a new tool we were testing to see if it was as effective as the old tools.
Here is an example of some of the list of words we were looking for:

Pictured: Examples of words Twitter was searching for.
All these things contribute to a score.
(Shows me on a video interview walkthrough of how the process worked)
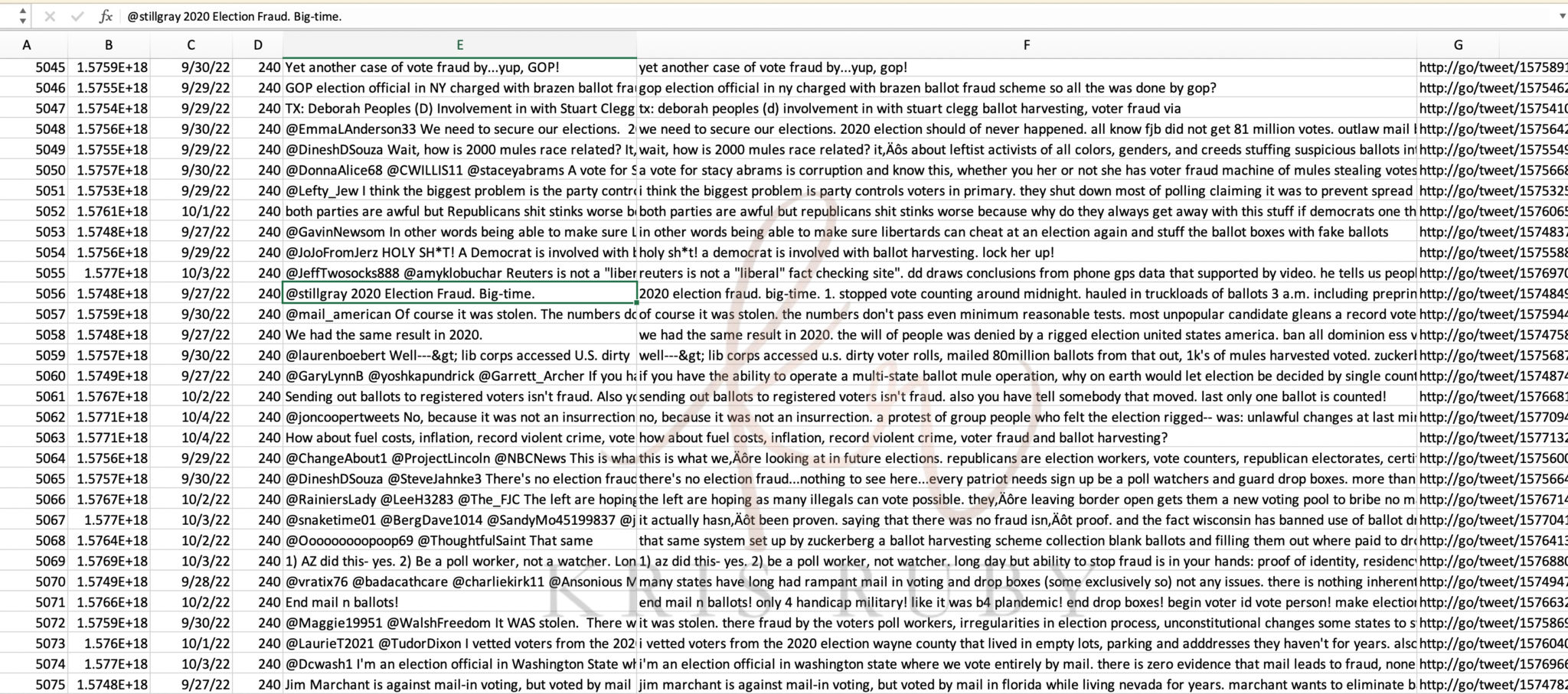
Example of flagged tweets:



Shows me more tweets:(the quote below is not related to the specific quotes in the above examples)
This person received a 160, which is just above the threshold of being flagged. You have to get a score of 290 or above. 290 means we have judged this tweet as the most likely to have misinformation, but it isn’t twice as likely as 150 it’s just more likely. 150 or above you can flag it automatically. It is not an absolute scale. It is not as if 290 is twice as likely as 150- it is just more likely.
We used models from SVM, to neural nets to look for these terms. It wasn’t one size fits all.
The baseline score is 0. A score of 150 or higher meant it was flagged. That’s why only 150 or higher is in the dataset.
Pictured: Twitter ML 290 ballot detections flagged tweet example.
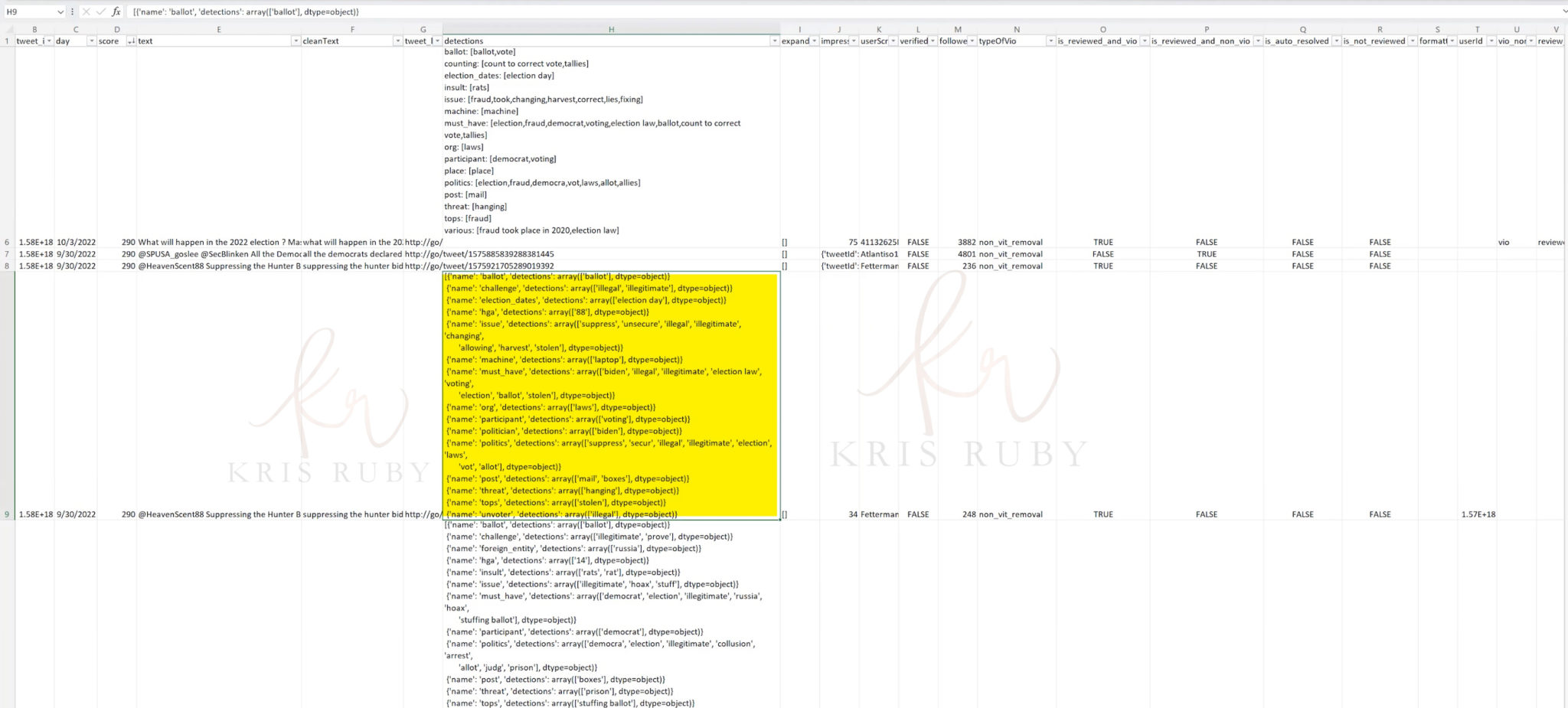
The detection list shows you what we are looking for with AI. The terms under the detection column are what flagged it (the tweet).
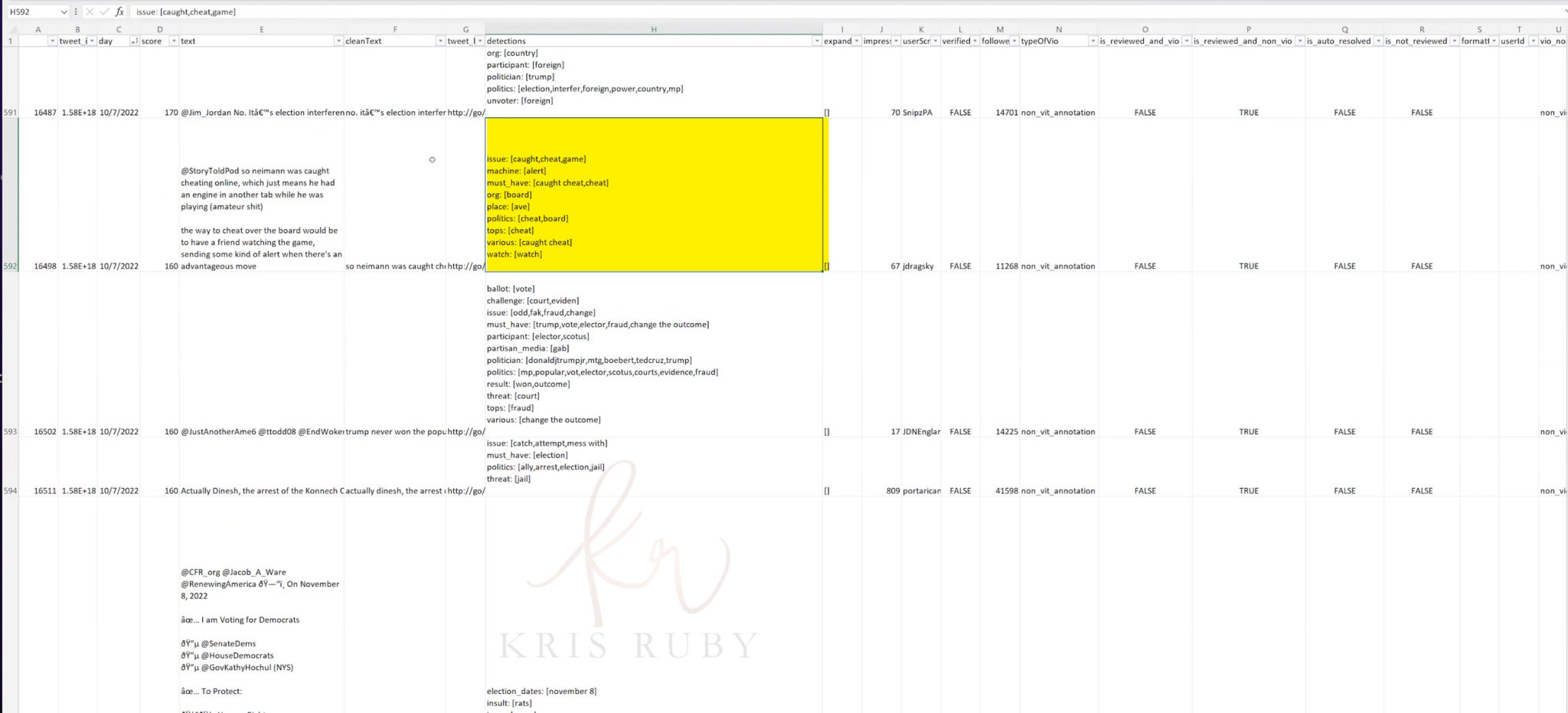
Pictured: Example of ML detection list at Twitter. Detections were words that Twitter pulled out of tweets with ML.
Caught, cheat, game, machine, ballot detections. All of these things (terms) contribute to the score.
We found this in the tweet that we then flagged that added up to the score of 290. If it’s 150 or above, you can flag it automatically. This is a straight NLP algorithm that removed this. Is reviewed and violated. In this case, it was false.
These tweets ended up being reviewed by a human at some point. Flagged, sent for human review, and a human said this is or is not worth removing. This tweet that replied to Warnock by Bman is reviewed and violated (false). This was found not to be in violation.
Detections- that is not me. That is not a human. That is the NLP- sorry. It is running in the background. We are always looking for this stuff (these words). Me and other people program it.
This is an example of a straight NLP algorithm that removed this content.
The computer shows: “Is reviewed/violated.”
Auto resolve. Did a human being actually look at this?
If it is auto-resolved, flagged, sent for human review, and human said this is or this is not worth removing.
Is reviewed and violated- false- found not to be in violation.
That’s not a human. That is running in the background. We are always looking for this stuff. Me and other people program it.
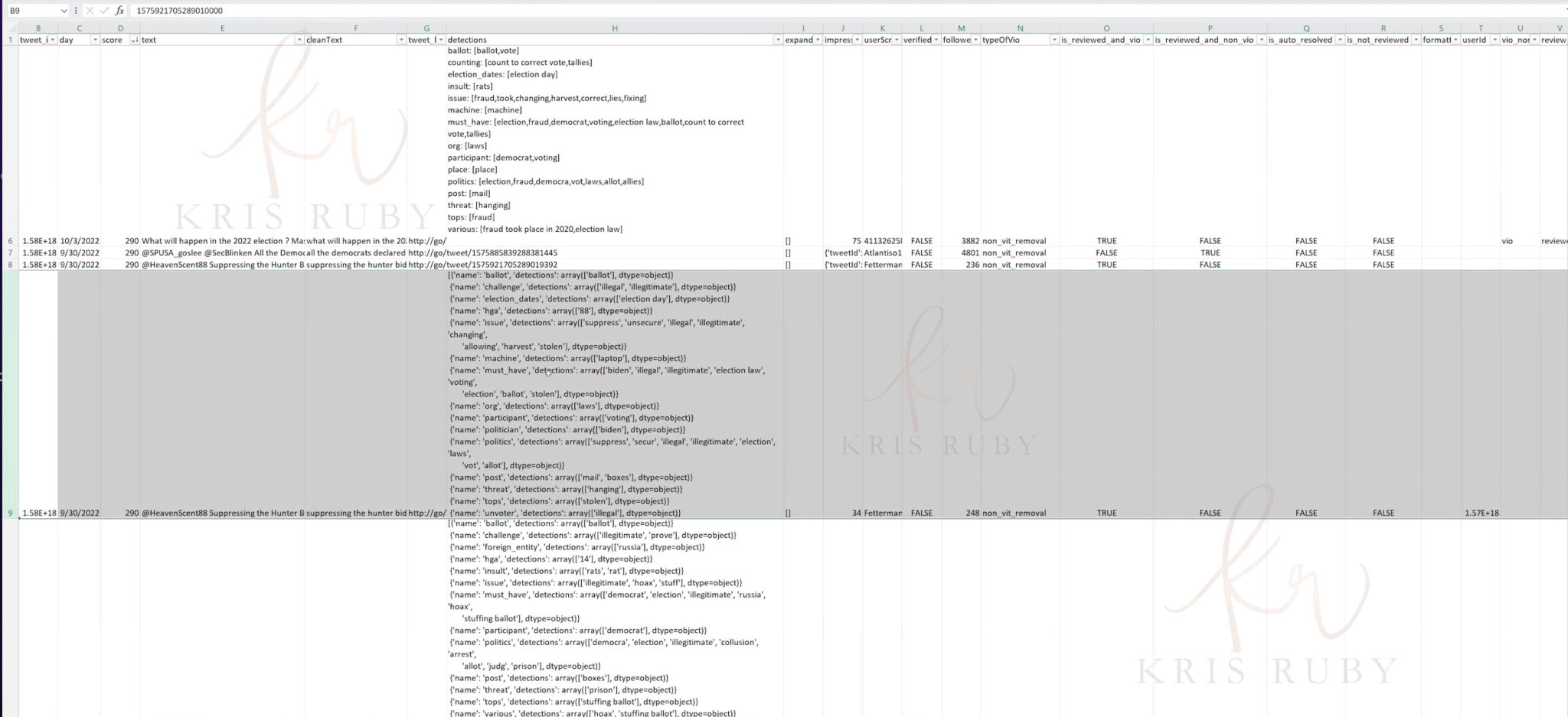
Pictured: Example of flagged tweet mentioning Hunter Biden laptop
This tweet is about suppressing the Hunter Biden laptop story.
If there are that many things- ballot detections, etc. These are all the things we found. That is what makes it have this score of 290. This was removed through non-VIT-removal our regular NLP algorithm.
How the model was trained:
The file includes actual tweets used to train the model. The n-grams sent were specifically being used as part of a model to determine if the entire tweet should be marked as misinformation.
All of the confusing column names VIT_removal, vio, non_vio, etc. weren’t put in manually. The annotations or bans had already been enacted and were being sent to human review. Those were records of what the algorithm had already done- not manually entered.
The detections went into building the score. Some were weighted more heavily. Obviously, we got some of them wrong, but we would send these to human review. They had the same terms they were looking for. So, it was a common vocabulary. That’s why we included them- for reference.
Regarding violations over time, we could break apart arrays and count how many times each term got banned. We could look at the data in the detections and look at the terms versus the score. We could look at how many times certain users were banned in that short time frame, etc. Nothing in isolation, but always in contact.”
Can you explain what we are looking at in this dataset?
“A list of specific tweets, some from large accounts, some from small accounts that were banned for the reasons you’re seeing in the files. You’re also seeing a list of policy violations and how many times they were flagged. This is the guts of the machine learning model at Twitter. It’s not pretty or simple. It shows the things Twitter cared about enough to suppress. You can look at the list and say “Nice job, Twitter,” or you can look at it and see Liberal bias.”
Hi @foxnewsmom Were you temporarily suspended on Twitter on or around 9/26/2022?
If so- what was the reason?
This is in regards to a story I am working on that is of public interest. Thank you. pic.twitter.com/5gTMbgdnoI
— Kristen Ruby (@sparklingruby) December 30, 2022
Where did Susan go? 🧐 pic.twitter.com/o7wUbIHpBY
— Kristen Ruby (@sparklingruby) December 30, 2022
Pictured: Actual tweets marked as political misinformation by Twitter.
These are tweets we flagged for removal algorithmically. Some were held up, some reversed.
We looked for terms. If there were enough of them – your tweet could get flagged. We worked with Trust and Safety, who provided many of the inputs.
But it is important to note that we also searched for context. These are words and phrases we had judged when in the right context were indicators of misinfo. Context was important because a journalist could tweet these terms and it would be okay. One or more of them was fine. In combo and in context they were used to judge the tweet as misinformation.
The files show internal Twitter policies that could be violated and how some specific tweets were actioned.
If you search for any tweet in the file and it’s not there, that means it was taken down. I found some where the account is still active but the tweet is not there. Real data is messy. Most of the tweets have a delay between tweet date and enforcement date. I think they told them remove this tweet and we will reinstate your account.
Babylon Bee misgendered Adam Rachel Levine in a joke tweet. He was banned for it and told to delete and they would be reinstated. They refused and then Elon Musk bought Twitter.
Look at the first two lines in political misinfo. The first tweet by someone named ‘weRessential’ which starts with ‘as we all know, the 2020 election…’ that tweet is marked as a violation. Column O ‘is_reviewed_and_vio’ is true. The user still exists. That account is there, but the tweet is not. It was a violation. The next line from screen name ‘kwestconservat1’ was also flagged but found not to be a violation. See the ‘is_reviewed_and_vio’ is false. That tweet is still up.If you filter in that is reviewed and vio column as true- you can look to see if the tweet is still there and if the account is even still there.
Sometimes a tweet was found to be in violation and then the decision was later appealed or overturned and the tweet reinstated.
- The misinfo tweets were already live.
- Is_reviewed_and_vio = true is the row to look at.
These were definitely violations. Many of these are no longer active (they were taken down). If you search the clean text of the tweet and it’s not there and Twitter gives you no results- that means it was taken down.Everything was taken down at some point. But users could appeal. Some appeals were granted.
So the very first line- it’s not there anymore. The second line is. Another example – I found someone whose account was up but the tweet was down. That is pretty good evidence, if not proof that these were tweets we restricted.
Another example in the dataset- “Yeah she got suspended by us.’
If the account is still up, but the tweet is down, it shows the tweet was in violation and they deleted it. How would you know what they tweeted except you have that spreadsheet of their data? She was suspended for the reason your file shows. That means it’s not a test. It’s real. It proves the terms in the list are real.
If your account was suspended, even temporarily, it is an enforcement. Would you rather be suspended temporarily or not at all? It’s a pain to go through the whole process.
They weren’t looking for tweets about An Unfortunate Truth. They weren’t suspending over the Jon Stewart movie. They were suspending over 2000 Mules.
If the cops come and arrest you and put you in jail any time you mention how corrupt they are but they always let you out, is that not still intimidation?
This proves the n-grams are real. The data allows people to objectively look at it and say, ‘look at all these tweets that aren’t there anymore.’ Twitter took them all down. That was pretty common actually.
Were public figure accounts treated differently?
“In general, if an account had over 10k users, we couldn’t suspend. It was considered a political decision then. As in Twitter politics. You didn’t want to ban Marjorie Taylor Greene, because it made you look bad to ban high-profile Republican accounts.
There were two sets of rules at Twitter. If your account had more than 10k followers, you could not be algorithmically banned. If a tweet from a large account was labeled an infraction- it went to a special group.
I don’t know why they didn’t tell people about the large account limit. If said in conjunction with other phrases, 2000 mules could cause someone with under 10k followers to be banned by the algorithm. But not someone with more than 10k. That would go to another team.”
How can one prove that these are real and were live?
“You have the files of policy violations and actual appeals. Why would you appeal a training data set? You have all these appeals for all of these policies. Those actually happened. People got their accounts suspended for violating those policies. You have the n-grams we were looking for. No one makes a whole model for their health. It takes work and time
Let’s say this was test data. What are we testing? Made up words? Why are we running tests on these n-grams? We could have chosen any words in the world, but we chose these. If I test, I want to see how my model performs in the real world.
This is a list of annotated terms from our AI. AI didn’t come up with them, but did detect them. These are not tweets people reported. These are terms we censored. We considered these terms to be potential violations. Even if they were ultimately held not to violate, they were things we looked for.
Does what we looked for show bias? Well? What do you think? All of these terms were flagged for later review. We took a second look. You have appeals data with actual policy violations. This is proof they were live.”
What does SAMM mean?

Pictured: Photo of policy violation in Twitter dataset.
“SAM means state-affiliated media. It might strike your readers as interesting that we were censoring information from other states at all. Some might ask what right we had to do that- you know? What if TikTok censored stuff from our government? Our goal was to keep election misinformation out. Some nations have state media operations- China for instance- which controls what comes out. They don’t have freedom of speech. If we judged their media to be spreading misinformation, we might censor it.
This image should policy categories and examples of actions we actually annotated across the world.
Delegitimization of election process means anything like stolen elections, double voting or alleging voter fraud.
Macapa is a city in Brazil. SAMM FC is state media in Brazil. There are actions on both sides we annotated. I will say we annotated a fair amount of Brazilian National media (SAMM), and I honestly don’t know enough about their media to know if it was politically one way or another. We performed an action of some kind of photos of Brazilian presidential candidate Bolsanaro posing with Satan (I think?) as well as claims of polls being closed or moved.”
How often did you adapt models?
“We adapt typically once a month or so, but as often as weekly when elections were near.”
Once a term is flagged is it flagged forever?
“No. We rotated terms in and out fairly regularly.”
How does moderation work beyond the flagged words?
“It takes all these ngrams it detects and generates a score that it tries to understand based on context. If it thinks the ngrams are likely a violation in context it will flag it. Sometimes the machine could ban you algorithmically, sometimes it would go to human review. Sometimes both a machine and a human would review. But again, keep in mind because of the sheer scale of data you need some type of machine learning.”
Does the machine relearn?
“Yes, we tune it as listed above (monthly or weekly).”
Does the data cover foreign elections?
“Yes, wherever we had enough people we did. We covered elections in the US, UK, EU, Japan, Brazil, India, etc.”
What about abuse content? I don’t see words pertaining to abuse in the file.
“I have a file on violations (not just political violations) and how many times it was caught each month. Abuse is definitely the highest. That would all be under abuse. One of the files I sent in the content moderation folder has a category_c column. That’s the main category. You can see that most violations are in abuse in that file. Within abuse, there are many subcategories – racism, homophobia, misgendering, antisemitism. There were different kinds of abuse specializations. They all had names like ‘safety’ or whatever. Personal attacks on non-public figures were abuse. We weren’t looking for abuse. I was looking for political misinformation. Two separate areas.”
POLITICAL DIVERSITY AT TWITTER:
How many conservatives were on that team?
“I don’t know that we checked. It wasn’t considered. My boss was not. I’m a liberal. Full disclosure here. Keep in mind the 3 legs of the stool. The people who help us understand the policy- ingest the research and work to set the policy. A group they work with. Those of us writing the algorithms. I’m not an expert at US elections and I’m certainly not an expert at other international elections I also worked on so that’s why we had to have these people to understand the issues.
I am finding them, but the strategy and politics/ health and safety people are giving them. We are in meetings with them. They say, these are things we are finding. Rewriting algorithms- how good of a job does this do? We also work with human reviewers to make algorithms better at the same point.”
Did you have politically diverse leadership during your time at Twitter?
“These things come from the top down, and if you had a more diverse team setting policy you might find a different system- meaning the things you are looking for.”
ELON MUSK, TWITTER, & FUTURE SOCIAL MEDIA PREDICTIONS:
Do you think this algorithm will remain intact under Elon Musk?
“That’s a great question. He is very concerned about reducing costs. Have some datasets been taken down? I don’t know what he’s gone through on the backend to change. He doesn’t seem to have a super detailed grasp on what his people are doing. None of us who wrote this work there anymore.
None of the original data scientists who worked in content moderation for political misinformation still work there. Undoubtedly, someone else has taken up some of the slack, but I don’t know who or what.
- Is this model still running?
- Is it (the model) being monitored?
- Is it (the model) just doing its own thing without control? (Human intervention/ oversight)
I don’t know. My boss was let go. The only person who is left decided not to sign the extremely hardcore email and he left so there’s nobody there.
Has it been removed programmatically? Have the models been taken down or altered?
“Before I left, there was a big push to get rid of extraneous datasets for cost reasons.
I don’t know now what is still there, but my personal opinion (without having current backend access) is that the removal of algorithms seems irregular at best. They placed 90-day windows on a lot of the datasets and ML work and you had to justify their existence- which, to be fair, was a good move.
If he (Musk) said we don’t want this- you would have to understand what the bot does. Something that runs automatically… I might call these bots. In fact, the original dataset was called U.S. bot tweets…things flagged by bots or algorithms. You would have to understand what it does in order to take it down.
I suspect that a lot has not been changed based upon what I’m hearing anecdotally. It doesn’t seem like he’s changed a lot. If this is still up- then censorship would still be happening. The midterms are done. We were most concerned with political misinformation around each country.”
It (the model/ detection list) was created by working with the Trust and Safety people who were the experts… with the government…with human rights groups and with academic researchers. That is how we got wind of these terms. We definitely worked with various government agencies. The government is a big place. Did we take requests from The Biden White House? I don’t have knowledge of that, but I do know we worked with certain government agencies who would say these were things they were seeing that were troublesome to them as we worked with government agencies around the world.
It’s a balancing act, because governments can also be significant sources of information. So we had to make internal decisions as to what was a legitimate request and what was not. They didn’t tell us the specific groups they worked with. We got it from Trust and Safety. By it I mean the terms and ideas they were concerned about and the things they wanted us to flag.
Yoel made decisions in the moment and I might disagree with the way that he handled the Hunter Biden laptop story but I do agree with the banning of Donald Trump. That is my bias. It’s fine. I wish that he was more forthcoming about how these policies came into effect and how he made them.
We looked for 2000 Mules. We weren’t judging it but the idea is- here’s the judgment. We found if you were tweeting about 2000 Mules, that tweet had a higher likelihood of having misinformation inside of it than a tweet that did not have 2000 Mules. That was one of the flags we used to look for that movie.”
Do you feel you actively censored people?
“I feel… I don’t know how to answer that we made some really difficult decisions and maybe not some great decisions but it’s a hard process. Do I feel there is bias? Yeah probably. I mean. Yeah. We had our own biases. It makes me sound like a monster when I say it out loud.
I wrote algorithms and made graphs and tried to see a high true positive rate of how good of a job it did at finding things.”
Is there systemic or algorithmic bias shown in the Twitter Files regarding political censorship?
“I’m gonna be honest with you. I agree with it. I think we did good work and I really wanted to keep the site safe. I can understand why people are mad. But you have to make a choice. We decided that saying the election was stolen and saying ballot boxes were stuffed and saying that Trump actually won was not really true. We have seen in the past the way misinformation can have an effect on voting and the democratic process.
In the past, we have seen the way misinfo could have an effect on voting and the democratic process. If you feel your election process is not safe, you might be less likely to vote. The idea was to prevent one person from being able to game the system. We want to avoid the situation where there is a government that controls a source of information. So, we worked with governments around the world, and we worked with human rights groups around the world, but we had our own standards. We tried to make these deliberative and careful and wanted to avoid any kind of harm that could come to the political process.
I agree with the decisions we made. Maybe that shows my bias, but I think we were right to ban people who said the election is a lie. I think it’s the right thing to do. If you feel that’s a bias and a terrible thing to say…You have to make a decision. It’s a really messy process. It’s not centralized. It’s hard and it’s boring.
The Twitter Files in particular are being shaped in such a way that there is a conspiracy. Everything in The Twitter Files… the shadow banning was talked about by Twitter in 2018.. this is our policy. We don’t consider it shadow banning. Regarding banning Trump..multiple people have talked about it. The Biden laptop story… Yoel Roth has spoken about that.
No wonder people didn’t trust what Twitter was doing. This dude (Jack) was totally checked out as a CEO. He didn’t care.”
Why are you talking to me?
“I want full transparency. I wish Twitter had been more transparent with their decisions. If you are transparent… they would not release the specific terms they were searching for. If you tell people.. this is what we are looking for and are open about what you are looking for then people can say whether or not they agree with that decision. You have to know what to look for.
I am trying to be open with you about the terms we were looking for. I have never shared any of this data with anybody. I am not supposed to share this with you, but it doesn’t matter anymore.
I want people to know, and you are the only one who has honestly even been interested in it.
Most of the media people consume is online. Search algorithms quickly tailor that so you only see your own biases reflected. To me, there seems to be a big divide in the Twitter narrative between who consumes what media, which is further polarized by the fact that no one watches both. My goal in doing this interview is for people to walk away and say, interesting. This isn’t the whole picture, but at least I know more than I used to and can have a more informed opinion on the topic.
Good, bad, or ugly, I want people to see what I did and my work so they can make their own determinations and judgments. I wish Twitter was more transparent. None of this should be a secret. The problem is that it is, and that creates polarization. We are still seeing people being banned or suspended, which makes me question how much has really changed on the backend.
Your readers may be upset with the lack of context in some of the files, but it is better to have something than nothing to look at. All of this feels like a semantic debate over AI vs. code. It is just one step in the process of what we reviewed. We tried to be really careful, and I believe we did really good work. If you know NLP, you should be able to recognize word stems as one step in the process. Showing code would also demonstrate ML, but that isn’t something that will be shared.
People are in their camps and don’t want to accept conflicting information. I genuinely wonder what people think the difference between AI and ML is. They seem to understand it as an issue of complexity with AI being more advanced than ML. What they aren’t discussing is how these algorithms can impact them both today and in the future.
I do believe in the work I did. I am liberal. But I didn’t set out to say, ‘I’m going to ban conservative viewpoints.’ I tried to ban what I thought was harmful.
I had a lot to do and trusted the process. You can see the insane number of terms we looked for and it was always changing. You can’t just ban a word. You have to understand in context.
There’s nothing I can say that is going to be a satisfying answer to a conservative who feels their viewpoint was suppressed. Except that it is maybe not as easy a job as it looks from the outside and I never targeted anyone.
It’s been dispiriting to see so many people objecting to the work I did. Some reasonably and in the spirit of debate, so quite passionately. But I know they only act that way because they feel aggrieved.
It’s important for my own sense of Justice to say the following: I’m politically liberal. I believed in the mission of content moderation at Twitter. I don’t want you, or anyone to think I’m giving the excuse ‘I was just doing my job’ But even if I didn’t set policy, I made mistakes. I want to own them. That is all.
I voted for Bernie Sanders twice. I have no political advantage to give you these. I have seen people make claims these are too perfect. Well, this is a liberal saying they worked on them. I care enough to try to make things better.”
What about child sexual exploitation (CSE) content on Twitter?
“People in my WhatsApp group are fighting over CSE. I have heard that Twitter’s CSE policy was not very good anecdotally and in a WhatsApp chat.”
Whose fault is that?
“Management. They didn’t want to put more people on the problem. This is Yoel Roth, Vijaya, and Jack Dorsey. They didn’t want to assign engineers and data scientists to tackle this issue.1-2 engineers in total were working on this issue. CSE fell under a different data science department. I have heard Twitters CSE policy wasn’t very good.”
Was AI was used to detect child pornography on Twitter?
“No. I don’t think so. I gather the AI used for child porn was not very well developed and underfunded. Child porn may have been under abuse. But it may have had its own category. They never devoted much manpower to develop it.
Members of the data science team have said, “We only ever had 1 engineer or data scientist assigned at any given time.” Some said they tried to warn others at Twitter. It was largely ignored and not prioritized.”
You’re aware there was an attempt to allow pornography as a paid service on Twitter? But they abandoned it because they couldn’t successfully detect child porn.”
🚨BREAKING:
In a private WhatsApp conversation on 12/9/2022, Data Scientists at Twitter stated they didn’t have enough people monitoring CSE.
In April 2021, leadership was warned internally about lack of CSE support. #RubyFiles pic.twitter.com/Goy06zlduc
— Kristen Ruby (@sparklingruby) January 1, 2023
TWITTER, VACCINE CONTENT & AI
Were you clear on vaccine policies and content visibility on Twitter?
“Hmmmm. It depends on what you mean by clear on vaccine misinformation. Twitter claims they were public. But who actually read these things? They were public though, as you can see in this blog post.”
On October 2, this tweet was marked for review either algorithmically or by a person.
Column b is policy. All of these are the specific policies we were searching for in U.S. political misinformation.
Look at the file ending in 1841871891. This was another attempt at time to action calculation. Still got it wrong. But look at column N. Lots of Covid related misinformation was flagged. The detections and flags show what we are looking for.
I see the word vaccine here. Can you tell me more?
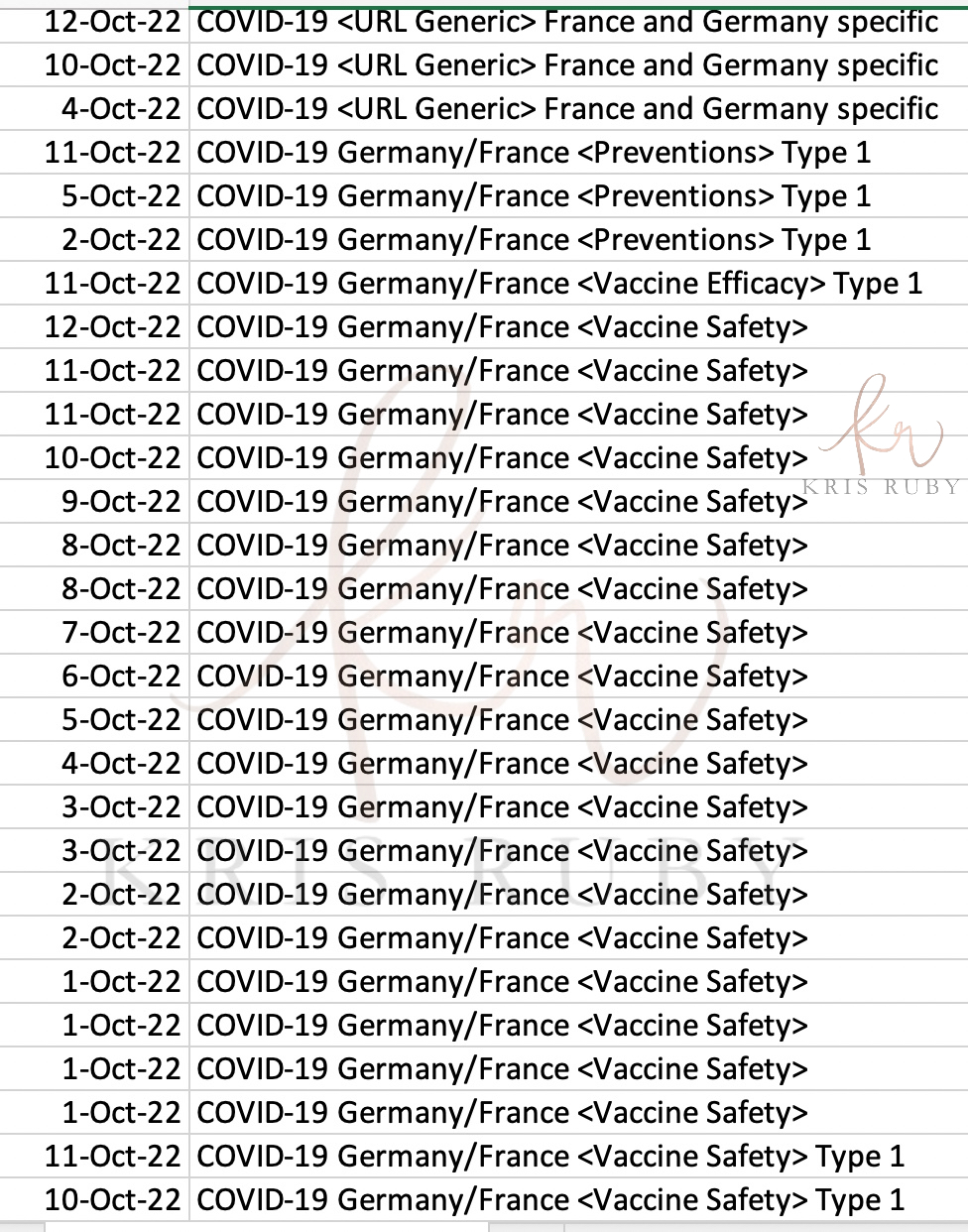
Pictured: How Twitter moderated content related to the pandemic. Example of content that violated a Twitter policy on misinformation.
“Misinformation about vaccine science as we defined it- vaccines are safe and effective. If you are disputing that and saying it is not- we picked up two places it is not.
These are the terms we looked for. If you violated our policy you could get annotated- meaning marked for further review.
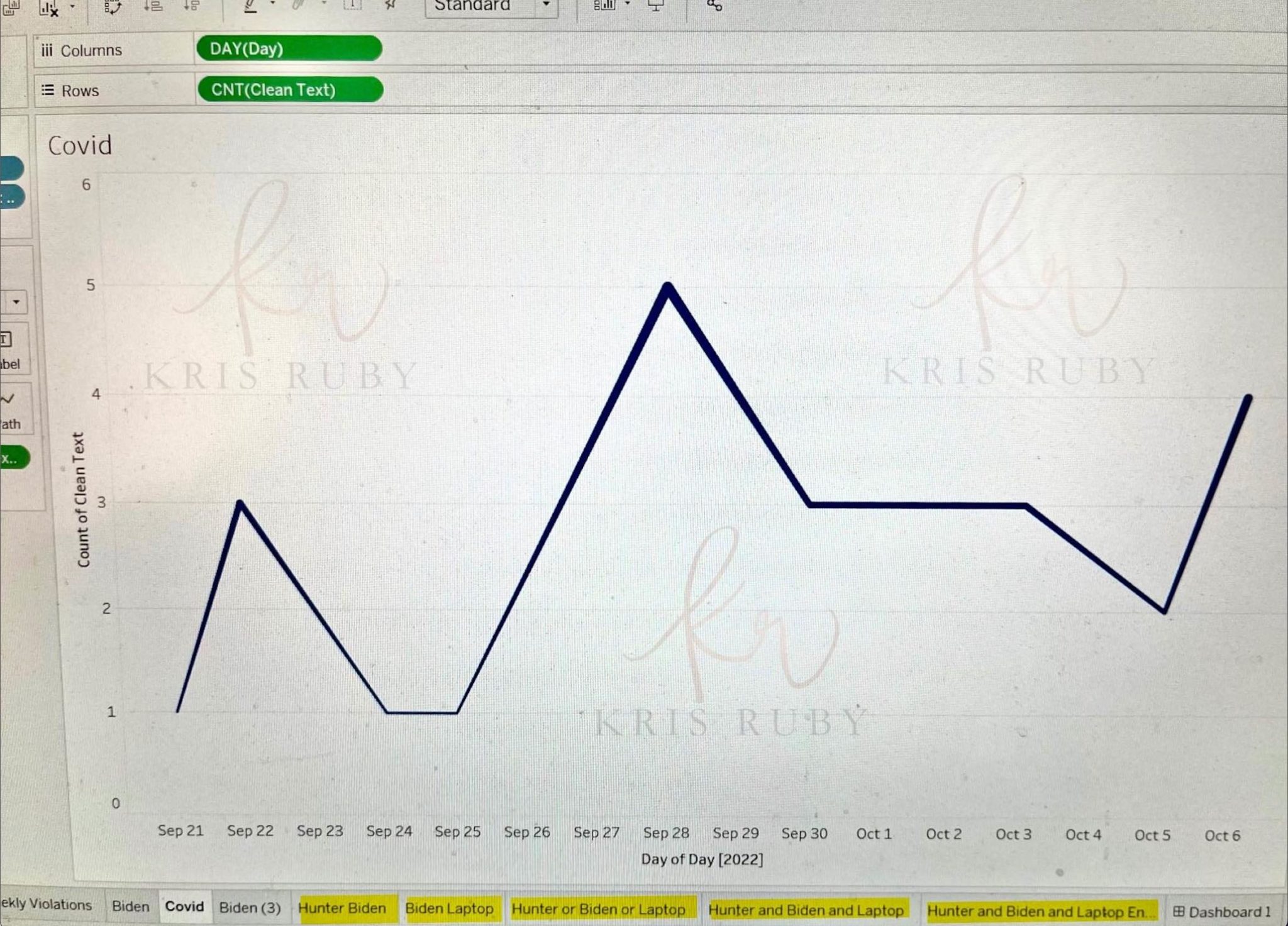
Pictured: Weekly number of tweets flagged by Twitter as Covid misinformation.
This helps us understand how prominent it is. By the time I left, vaccine misinformation tweets were hardly occurring at all. We were flagging them very infrequently I should say. You can see that in the number here (shows me on screen data).
I wish there could have been a robust discussion of Covid treatments, but things quickly got politicized around that.
The vaccine direction was one hundred percent Trust and Safety. We were working with The CDC and different government agencies. They were saying the vaccine is safe and effective and we think this should be a term you are searching for.
We checked for terms related to Covid. By Oct 2021, there wasn’t as much on the site regarding it. We would flag it under the following circumstances.
It had a political component – this was usually about government policy, lockdowns, etc. and there was misinformation about harms it caused. The lockdowns or whatever. I didn’t deal with vaccine stuff itself. Only as it applies to politics.”
The CDC told you what to search for?
“Among other people. Yeah.”
What do you think about that?
“I don’t think of it as being pressure. I think of it as one of many sources we gathered information from. That’s how I conceptualized it. You have to choose who you trust.
I disagree with the fact we censored the Hunter Biden laptop. That was censored. We were terrified of another 2016 happening, where the perception was that things that were released on Twitter shaped that election. You can judge whether you think it’s good or not but that’s the perception at Twitter.
The 2016 election is what caused us to form our safety division in the first place. Content moderation was much more decentralized before that. That was the inciting event- we thought- this looks like its Russian disinformation again- we should censor this story.”
What do you mean by another 2016 happening?
“The perception was that things that were released on Twitter shaped that election.
There were emails released from WikiLeaks leading up to the 2016 election which painted Hillary Clinton in a negative light and contributed to her losing the election. Personally, I think she is a terrible candidate. I think that’s why she lost. But that was the perception at Twitter was that the events related to the leak of The DNC emails were one of the things that swayed the election.
They didn’t want to share it because it was illegally stolen information regarding the emails- but it did get shared. That’s why content moderation under Trust and Safety started. It was much more diffuse prior to that. There was a generalized content moderation board, but it wasn’t a high priority focused area.”
They didn’t want to share the news or they didn’t believe the news was real?
“Yeah, they didn’t want to share it because it was likely illegally stolen information.”
How many people supported Trump that you knew that worked at Twitter?
“I don’t know. Everyone I knew was a democrat or a liberal.”
Why do you think they wouldn’t want people to know the terms they were monitoring?
“Yeah. Why? They feel it would let people game the system. If you know what you are looking for, you can find ways to circumvent it. It’s the same reason Musk floated he would make Twitters’ algorithm open source. That is not a good idea because then people can hack it and do all kinds of stuff with it.
I believe the public has a right to know if you want to disagree with something we did.
Did we support child sexual exploitation? Of course not.
Did we devote enough resources to it? No.
We should have devoted much more. It wasn’t a priority.
Did we attempt to ban conservatives? Well we worked with people who told us these are search terms you should look for.
There is a lot of speculation. I want people to have a clear picture, even if it makes me look bad.
We didn’t consider it explicitly politically disadvantaging one group.”
Is it possible to truly measure algorithmic bias?
“Yes. 100%. Bias in an algorithm can be measured. For an algorithm, bias is the difference between the actual value and predicted value. A measure of error. That is not too difficult to check. But I’m not taking about that. We are talking about human bias. The belief that my frame of reference is the correct one. There is no algorithmic way to check for that.
Let’s say I think vaccines are the best treatment for Covid, and people who try to spread alternative treatments such a herd immunity, ivermectin, or hydroxychloroquine are dangerous. I train my algorithm to suppress those, because I genuinely believe the vaccines are safest based on the data I’m using.
If I believe the stolen election theory is a lie and dangerous to democracy, I try to suppress it. I don’t think checking for mathematical bias is going to do anything.”
What about Twitter’s decision to suspend Donald Trump?
“Just to be clear, I do agree with the banning of Donald Trump. It was a very controversial decision to ban the President of The United States. There was a lot of fighting internally.”
Do you think you censored equally?
“Uummmm. Nope. But I want to suggest something. Twitter released a study in 2021 where they said we are amplifying right-wing voices more than left wing voices. Both things can be true. You can amplify and censor them. Both can be true. It is also possible that there was more misinformation and extremism concentrated on the right than the left.”
Would you ban DNC terms under Elon Musk if he said I want you to ban anything Antifa related?
“Would I do it? I guess I’d do it. I don’t know that I’d be attracted to work at a place that I felt did that. Censoring leftist stuff or mentions of Black Lives Matter. I believe in those things. I would push back. What say do I have in these things anyway?”
I don’t think Elon Musk is being transparent. Kanye West tweeted a picture of a swastika. Is that an explicit call to violence? Is it? I don’t know. It seems like the decisions he’s making are just for him and things he doesn’t like, which I would argue is not better. Even if you think what we did is reprehensible, don’t think what he is doing is better. He is less transparent.
People from Trust and Safety are resigning and the decisions now rest in one person- him- and he is mercurial. I don’t think he’s being transparent about what he wants to do. He wants to drive engagement and he doesn’t care about right wing or left wing. He just wants a lot of people to be on his platform.”
Do you have any concerns on how AI can be used by the right to censor the left?
“I don’t know Musk’s politics. He is vaguely right wing (kind of). But how does he feel about the right to bear arms? How does he feel about states’ rights? I don’t get the feeling data privacy is a primary concern- that is just my personal opinion, though. Where does he stand on religion? We saw him rewrite the rules in real time to ban and temporarily suspend several journalists. What is to say he won’t ban anyone he wants to at any time? And what is to say that he won’t use AI to do this in the background? People worship him and follow his every move- but do they truly understand the moves he is making from a technical level? And furthermore, does he? I am not sure he even knows what he means sometimes.”
Do you believe the media has sufficiently covered how Twitter leverages AI?
“I have done interviews throughout my career, and not a single reporter has asked me the questions you have. Your technical background in the space serves as a buffer to help people understand and somewhat mediate highly technical content. You can’t ask what you don’t know. Simply put, you can’t ask something you don’t know you should ask if you don’t even understand the topic you are asking about. This is why no one covers it- despite it being critically important to any discussion on social media content moderation.
These are complex issues that can’t be boiled down in a tweet. Also, if any individual data scientist tries to contradict what is being said, they will not have his rank or pull and he can easily shut them down. Who are you going to believe? A data scientist you have never heard of who says things you don’t understand or Elon Musk? Many PhDs do not fully understand how NN works. You can’t pick this up casually on Twitter. It is intense to learn. It is why you need to get a masters in it to implement anything.
We previously used NLP at Twitter. It seems the only difference is he is using a different algorithm. Musk is a super smart guy who understands a lot, but it also makes sense he may not know all of the ins and outs of the field. When he is not clear, it creates confusion- and without details, all we can do is guess at what he means. I do believe it could be dangerous to try to run content moderation with so little staff. A few days later, we saw hate speech jump on the platform. But remember, if the algorithm has been changed, and the definitional term of hate speech has changed, that will impact the data, as well as how it is reported. It would be akin to measuring two different things, with two different systems.”
Some people have called Musk’s recent NN downvoting system akin to a social credit system. What do you think of that?
“No. It is not. Regarding his most recent tweet on downvoting- what is a user action? What is positive vs. negative? A tweet? A like? A RT? A DM? Hosting a Twitter Space? Community notes? From a technical perspective, positive and negative user actions have to be defined if he wants to promote transparency. If not, nothing has changed, other than the algorithm and the terms it is possibly flagging.
There will be a ton of scoring issues — which is the same as before. If it is just down votes, that’s not a neural net, is it? There are more questions than answers, making it almost impossible to guess at some of the things he is saying without drilling down into the details. In an academic setting, neural nets take a long time. Some of his tweets make it seem like they are crowd sourced new ideas- but we know from the backend that these things take a long time to train and develop. So how long has all of this actually been training for?”
Both NLP and Neural Nets are AI. NN is famously resource intensive and takes a lot of time and computing power. It’s not necessarily bad if you’ve planned for it. You have to have already made decisions about what’s positive and what’s not and then train it on that.
People don’t want to accept that you need some machine learning to scan a dataset as large, varied, and frequently changing as Twitter. And that means someone has to decide what counts as negative behavior.
A neural net compares every single data point in a set with every other. It is extremely intensive and comes closest to matching human reasoning (hence the name). It uses either forward regression or backward regression to check how to improve itself at each step. It generally needs billions of rows of data to perform maximally, which Twitter definitely has. However, there are many unanswered questions as to how it will be implemented. It’s another way of doing things. It still needs a human to help it make judgments in that it’s a supervised machine learning process like NLP.”
Twitter recently announced a new policy around the promotion of alternative social media platforms. This policy has since been deleted.
“Going forward, Twitter will no longer allow free promotion of specific social media platforms on Twitter.”
Do you believe AI would be involved in this process for it to work at scale?
“Yes. There is some programmatic way to do it. In other words, not manual human review.”
Does it take a long time to train?
“Yes.”
Elon Musk recently described Twitter’s former AI as primitive. Do you agree with this statement?
“No. Our AI was some of the most advanced I’ve ever seen. We needed to track real-time data of enormous volume- something like 37 million tweets per hour. The AI has to be powerful and flexible to keep up with that volume. Also, there was a huge variety of data. We called it multimodal data – a tweet could have text, image, or video and we would need to decode and measure all of it nearly instantaneously and to decide if it violated a policy. So, compared to Meta (Facebook and Instagram), we didn’t have as much resources thrown at it. Meta would say their content moderation team was bigger than the entire workforce at Twitter. That’s true. So, we certainly didn’t throw as many resources proportionally at it. I think many on the right think we should devote even less, but those we did have were best in class.
We used AI and it was very complicated. Everyone working on it there has a masters or PhD and many years of experience in the field. We can’t show code, but it is certainly ridiculous to suggest it was easy or primitive. He has spent his entire time there diminishing any work we did prior. We still have no answer on whether or not anything I have shown you here is still running. If it is, and you believe the data is biased, then you will not believe Twitter has free speech, and you will believe Twitter is still engaging in censorship.
Is he saying they changed the algorithm in a month? I don’t know. But also, he doesn’t know if the old NLP is running (based on his answer) and functionally, Twitter appears to be exactly the same. What am I missing? I don’t know because we don’t hear from anyone there except for him. No one is there to dispute him. He has the mic. This becomes dangerous when talking about highly technical aspects of ML/AL that you typically need a PhD for. He doesn’t know what is running. When asked if it has been rewritten he dodged the question. I don’t mean to be crass but- he has no idea what is running on his site.
Imagine getting jail time for putting out a list of words? This is where we are at when things aren’t open source and in public. Sharing this data shouldn’t be as dangerous as it is.”
What do people not understand about big tech, AI, and social media platforms?
“There is no such thing as neutral AI. We have to get away from relying on AI as a single source of truth. It performs a task we train it to do. Especially in something like NLP, which judges human speech.
Musk recently stated, “There is great danger to training an AI to lie.”
There is great danger in training an AI to lie
— Elon Musk (@elonmusk) December 24, 2022
Do you agree with Musk that there is great danger to training an AI to lie?
“He is just pretending he can be above it. Musk has experience in self-driving cars that use computer vision and identify visual patterns. The first commercial application was Optical Character Recognition for the USPS. Musk’s Tesla team uses it for their self-driving cars. Is there bias in that? Yeah. It’s just not reflected politically. But when you are dealing with something like NLP, you are making a judgment.
You need to make a choice and can’t pretend you’re letting the machine do the work for you. The machine is doing the hard work, but you are the one who told it what to look for. It’s disingenuous to claim you can make it impartial. Because you made a choice. The output will reflect the input choices made.
I would never say AI is trained to lie. However, I would say there is bias that exists in training data. The type of bias that is happening (and that he is referring to) is called prejudice bias. In this example, someone at OpenAI doesn’t want to promote fossil fuels and thinks they are dangerous. They have programmed the model with that bias. Bias can be implicit (you don’t realize you are biased) or explicit. Someone has explicit bias against fossil fuels. The output will reflect that bias.
At Twitter, we explicitly looked for certain things, but implicitly controlled for others.
Implicit bias – I genuinely felt MyPillow was a good N-gram to look for misinformation. So, to me, I wasn’t trying to squash the right. I just saw tweets with those words in it were more likely to mention stolen election or put the democratic process into question. But we could have worked with some people on the right to set up an appropriate control. Maybe Musk is right and we don’t need to look for anything.
If you set up a list of prohibited terms for OpenAI – it famously won’t let you sing the praises of Nazis – you can control for mention of those terms. It analyzes the sentiment of your input by breaking into n-grams, trying to understand what you’re asking. If it sees you’re trying to praise something it doesn’t like – it can stop it. The implicit bias example is engineers classifying ‘trans’ and ‘lesbian’ as search terms for porn. So, they couldn’t be used. That was in 2015 or so. Then people pointed out actual LGBTQ people exist and maybe we shouldn’t classify their existence as porn. The engineers weren’t explicitly biased, they just didn’t have exposure.
The OpenAI prompt where it wouldn’t write an essay on the benefits of fossil fuel? AI. It’s unlikely that someone took the time to hard code in every conceivable scenario they didn’t want their AI to do. That’s literally the point of machine learning. But you could also just have a banned word list.”
Did you see the new Twitter Files release that mentioned the FBI monitoring search terms?
“I am so sick of these Twitter Files I don’t even notice anymore when they come out. My guess is that The FBI would request they search for instances of those terms. Yes, it uses AI, but I didn’t work on that part. My guess is it works like Amazon Elastic MapReduce or BigQuery, which sample portions of the whole and extrapolates. That’s just a guess.”
Do you have any insight into the content moderation process mentioned in The Twitter Files re moderators in The Philippines?
“The contractors in the Philippines were the human reviewers. I don’t have a ton of insight into their process, but following a flow chart or decision sounds plausible. But I don’t really know. I know they had some sort of process they followed. And yes, they were non-experts. What do you want to do – employ doctors or nurses with specific medical training to do menial, repetitive work?
Many moderators in human review were contractors. The human reviewers had lots of training docs. I just don’t have access to them. It would be great for people to see them. That would do wonders for transparency.”
What is the solution to ensuring a reduction of algorithmic bias on social media platforms?
“Increasing diversity at the site council or among those who are responsible for writing policy. We had a Trust and Safety council at Twitter that advised on which terms to look out for or ban. Elon Musk recently disbanded the entire council after three members quit. They weren’t the people making decisions, but they did advise us. In the future, the humans who advise data scientists on what terms to look for should be chosen with greater political diversity.
We worked with many people on Trust and Safety. If there isn’t political diversity – you get ideas favoring one group or the other. We are incredibly polarized in The US. On both sides, I think. To me, lack of diversity pushes to the extreme, and all of this can be further amplified with algorithms. If you felt old Twitter was extreme left it’s because we were all leftists, or a lot of us were. I don’t think most people really support extremism, but when you are in an echo chamber, it’s easy to amplify your beliefs.”
How could things change in the future on a management level to ensure there is no algorithmic bias?
“Bring it up in a meeting to discuss with leadership. Most bosses are fine with some discussion, which we didn’t do before. We just accepted it. So, when I got fired and spoke up, a lot of people attacked me. But some people presented reasonable questions, too. And then when I spoke to you, you were like, “doesn’t this seem like bias?’ So, I thought about it some more.
I understand now, in a way I didn’t, that this is seen as bias and why it’s seen as bias. I am now more aware of it and interested in the need for balance. If I had my way, choices would be my own and deliberative.
Individual decisions account for collective responsibility. Many people made decisions that impacted algorithms including Trust and Safety, Legal, Site Council, Data Scientists, Content Moderation. Musk is the CEO. So ultimately, the responsibility for deployment of ethical AI stops with him.’
Do you know if algorithms have been removed or modified?
“Do I know whether or not things have been taken down? No. The removal of algorithms seems irregular at best. He let people back on the platform, but didn’t change any of the algorithms. Some of the words in are still being flagged. I see people are still being suspended and do not know why, so you can see this is still happening.
Only the furniture got moved; the house is still the one that Jack built. Airing dirty laundry isn’t the same as fixing the issues. If these words are still being flagged, then it’s still old Twitter, despite what he says.
In my opinion, he doesn’t have enough data scientists to tune the model. We warned him content moderation needs bodies to run it.
You don’t just build a model then release it. You have to test and tune it. You have to see if increasing certain hyperparameters makes it perform better. Hyperparameters are things like gradient, which is how large a correction to make for errors, or folds, or weights. Stuff intrinsic to the model. You have to look at what is falling through the cracks. False negatives. And what is being classed as a violation incorrectly. For example, the tweet about hostage luggage, which is a false positive. A false positive: I say a tweet is a violation (it’s positive), but it’s not really (false). It takes time and bodies- and he doesn’t have either.”
Do you agree with the recent policy decisions Musk has made?
“It’s bad news for transparency if he is suspending journalists based on arbitrary policy, or if he continues to change public policy daily. He wants free speech, yet the people Twitter is suspending are not threatening violence. It feels targeted. I believe he is threatened at times because he is afraid certain things mess with the narrative he wants to portray. It is really hard to know exactly what he means. He is not being transparent. I am not even sure that is intentional. He moves very fast and I think what he wants changes daily.”
Sometimes he also comments on topics outside of his scope. Coding is hard and no one expects a CEO, even one as brilliant as Musk is, to be able to code in every discipline. That being said, some things he says don’t make sense to me. He simultaneously wants to monitor lines of code written, but also thinks there’s too much code. On a recent Twitter Space, he claimed that he could roll out an entirely new system from the ground up with no downtime. That seems insane to me. It would take a long time and involve many people across many departments. I have been involved in many data migrations and each time it took 6-9 months. To redo everything, it would take a very long time.”
Musk’s recent actions are commensurate with those of a person who has no idea what they want and is flailing around. But it seems impressive to people who don’t understand how things work from a technical perspective. I wish he would spend as much time making Twitter better as he does trashing the old Twitter. I truly want Twitter to succeed. Trashing everyone who previously worked there doesn’t help the platform succeed. I don’t think he realizes we are proud of what we built, and we don’t want it to die, even if we no longer work there. People may not like him, but that doesn’t mean they dislike the work they did before he got there.
Everyone has dug into their positions. I wish he was being more transparent, but I also wish others were being more transparent, too. I wish more people were talking, but they won’t, because they are afraid and also need to find jobs.
Is he intentionally trying to crash the company? I don’t get it. I still want Twitter to succeed. Does he? It is hard to know what he sees or cares about.”
*********
RUBY FILES: MY TAKE, COMMENTARY & ANALYSIS:
What stands out is that artificial bias may have indirectly influenced and impacted artificial intelligence inputs, which resulted in flagged words, temporary suspensions, and a lack of checks and balances on the internal vocabulary used in the training model and data.
For Twitter’s public display of valuing and prioritizing diversity and inclusion, it is apparent that Twitter lacked basic political diversity in the teams that created these critical datasets that dictated speech on the platform pertaining to US political misinformation.
After further investigation, I learned that Trust and Safety was directly impacting the work of Data Scientists at Twitter, frequently asking them to modify word lists per their discretion. The CDC played a significant role in the creation of these word lists for machine learning during the pandemic as well as academic researchers.
Data Scientists relied on the best judgment of government agencies to dictate the role of misinformation when fine tuning their models. In hindsight, this may have been a mistake. Data scientists were not empowered to speak out and trusted the experts that the words they were told to monitor for were in fact misinformation. Why did Trust and Safety and The CDC play such a large role in the Data Science and Machine Learning functions at Twitter?
The phrase ‘trust the experts’ must also extend to the expertise of machine learning, too. Did anyone trust the expertise of the data scientists, or were they used to amplify the political beliefs of the government at their behest? This is a dangerous and chilling story of the weaponization of social media into the area of machine learning. These decisions have far reaching consequences.
Furthermore, the fact that Twitter used machine learning to flag other media outlets as “partisan media” raises additional flags for antitrust legislation against big tech. If the ML is automatically weeding out other media outlets as partisan, how can those media outlets stand a fair chance at competing in the market against Twitter?
Low Follower Accounts Were Treated Differently Than Public Figures
While the national conversation on free speech focuses on high-profile executives of tech companies and how content decisions are made at the public figure level, these discussions rarely focus on how content decisions are made at scale for non-public figures, and the role artificial intelligence plays in content moderation.
The increase in user-generated and AI content has outpaced the number of human moderators to police information that is deemed as dangerous hate speech. In the future, the majority of content moderation decisions will be made with AI. But the future is now.
Most of these decisions are already made by AI, whether you realize it or not. Artificial Intelligence and automation optimize the content moderation workflow with large-scale machine learning algorithms and fine-tuned data sets.
In a recent Twitter Space, Musk stated that the general idea of giving access to company documents was to surface anything bad Twitter had done in the past. However, it appears that almost no access was given to reporters for any internal company documents that exhibit algorithmic bias, which is why these files are so critical to understanding the full picture.
Based on the data, there also appeared to be two sets of rules for high-profile accounts vs. non-public figure accounts. From my preliminary analysis, it appears that high-profile accounts had a lot more leeway with using the flagged words than unknown accounts did who used the very same phrases.
Instead of debating the semantics of AI vs. ML vs. code, we need to collectively examine what words were deemed as political misinformation and why.
- Who created those words?
- Did they show algorithmic bias?
- Has the data been retrained?
While this article focuses on Twitter, none of these issues are unique to Twitter. Every social media company is deploying artificial intelligence for machine learning, and many big tech companies have a lack of political diversity in the data that is being trained. That lack of political diversity is directly reflected in the input of data as well as the output.
The solution is political diversity in data scientists who are making these words available to the public so they can engage in a discussion about free speech by having any and all information disclosed to them about what that actually means from a technical perspective. However, that is not as easy as it sounds. Data is the new oil, and every company will want to keep their model close to their chest. To reveal their model would be to reveal their secret sauce. So even if a company provides a list of stop words or banned words, that is not remotely the same as revealing a list of n grams for their ML model. People continue to conflate the two, which misleads the public. One is a static object; the other is engaged in active learning and training.
Ethics in Artificial Intelligence on Twitter
Who determines what is considered harmful content?
Machine learning can classify harmful content automatically. To understand this process, you need to know what the algorithm deems as “harmful content” in the first place. Content filtering and natural language processing is deployed at scale, and content moderation is largely conducted through automated review (not manual human review).
AI-powered systems can classify potentially harmful content as hate speech and make automated decisions to manually moderate the procedure with the goal of eliminating human intervention unless necessary. For example, does this truly rise to the Trust and Safety level? For public figure accounts, the answer is yes. But for everyday non-public figure accounts, the answer is a resounding no.
Who is training the systems and what data is the system trained on?
The FTC is clear that if AI is used to make decisions, consumers must know about it. While this article focuses on Twitter’s use of AI in content moderation, the big picture is that this is happening at every social media company.
Over the next five years, the rise of no-code and low-code AI tools will create these problems at scale for every business.
As a business owner, you may be wondering how all of this applies to you. Pretty soon, you are going to be in the same position to make significant decisions about data that will impact your customers, and trust with your consumers. We are not that far away from that point. Let this be a lesson in PR and transparency.
How AI Works With Content Moderation in Big Tech
Limiting the reach and visibility of content at scale
When we discuss ethics and bias in AI, it is usually relegated to people saying that AI is trained to be racist or hateful. But what if the AI is also being trained to have a political bias that can impact elections, censor critical news stories, and remove people from the digital public square?
What if in the quest to fight misinformation the people at the highest level of trust and safety are actually misinforming the public about what misinformation even is?
Is that not a form of harmful bias, too?
The weaponization of AI will wreak havoc on our political system. In the future, wars will be fought differently, and as I have said for years, those who control the algorithms control the messaging.
Bias in AI does not only mean stripping datasets of “hate speech.” The bias in the input of what is manually put into a machine is just as important as what is removed from it in the output.
It is important to call out left-leaning bias in AI, too. For example, I recently purchased an AI tool trained for PR professionals, but the media outlets it has been trained on are primarily left-leaning publications, and the famous quote sections that the AI was trained on is from Democratic Presidents. This means that left-leaning bias is actually being built into the AI from the ground up. It is not being stripped out; it is being built into it to reinforce political bias.
Programming AI with your personal beliefs at the expense of your customers without them even realizing you are doing it is a problem. The data clearly shows this was happening at Twitter under former leadership. But more importantly, this is starting to happen in AI/SaaS, too, and no one is calling it out. Indie hackers, engineers, and developers are fine-tuning AI to their personal political preferences without consumers even realizing it.
Bias in AI is not what the left deems as bias. We must come to terms with this fact and work off a unilateral and bipartisan definition of what bias in AI means and looks like in the future. If you program AI to intentionally exclude Republican candidates and conservative media outlets, you are building AI products with bias baked into it. That no one in the media understands this because the majority of reporters aren’t developers does not mean you will get away with it.
This is the real cover-up story of the century. Not that information was covered up, but rather, that entire datasets are hidden from public knowledge without you knowing it. The Twitter Files are a distraction from the real issue in Silicon Valley.
What is happening at Twitter behind closed doors is taking place in every big tech platform in America right now. This is the story. This is the smoking gun.
It is clear that Musk has a high level of animosity towards legacy institutions including the corporate media and journalists who fuel the digital publishing ecosystem. But make no mistake- taking power away from legacy institutions means giving new power to someone or something else.
In this case, it would be machines.
Musk must clearly state how he plans to use AI, and if users will be part of a mass-scale training set. Proprietary data is gold, and no one knows this better than Elon Musk.
Could Musk have purchased Twitter for access to this data, rather than to save Twitter? What does saving Twitter entail? What, if any, freedoms do we lose to save the concept of free speech? What has to die for Twitter to be saved?
Does free speech cost eight dollars a month?
Does free speech cost license rights to a proprietary training set?
Historian Jason Steinhauer states, “Twitter will become for Musk another form of leverage in the battle to take power away from legacy institutions he sees as unjust or illegitimate. PayPal took power away from traditional financial institutions. Tesla has taken power away from fossil fuel companies. Now, Twitter will seek to take power away from journalists and media companies, a sentiment that will delight many in Silicon Valley who have been considering doing the same.”
Twitter is a massive data set, which could be used to train Musk’s other AI platforms. This data is worth significantly more than the amount Musk paid for Twitter.
If you take power away from something, it must be replaced with power towards something else. This is the law of gravity. What goes up must come down. Musk is not clear about where this power is being transferred to. No, I don’t believe it is “power to the people.” I believe it is power to the machines.
While this can be a very good thing if used in the right way, for the sake of transparency, he must share explicit details on how AI is being used at Twitter and what words are part of the parameters for future detection and content moderation list at scale.
It is easy for Musk’s base to get swept up in his heroic claims of saving free speech. But if he wants the base to believe that, then we need data to show what has changed on the backend. Has he removed left-leaning algorithms that were allegedly programmed? It is not enough to take his- or anyones- word for it.
Without hard data, free speech is merely an AI-generated response. How can we differentiate Musk’s definition of free speech from one written by ChatGPT?
Data.
For free speech to have meaning, we need to back it up with scientific data that shows how speech has changed over time since Musk took over. That starts and ends with comparing and contrasting algorithm changes.
A nuanced counter narrative to the Twitter Files
What stands out in the data?
Partisan Media: Twitter dubbed Telegram, Fox News and Newsmax as partisan media outlets.
In my opinion, this raises significant legal and antitrust questions, particularly regarding Telegram being flagged as a partisan media outlet.
Data scientists looked for entity relationships to connect the content to other semantically related entities, which Twitter believed was a sign of misinformation. As the saying goes, it’s not only what you know, but who you know.
On Twitter, the same holds true. While high profile accounts may not get flagged, accounts with under ten thousand followers using the same words might.
The documents obtained show a clear pattern that Twitter was actively shaping public opinion through machine learning and algorithmic bias. This was concealed and never publicly made available, despite Twitter stating it was. What is even more startling to note is that Twitter frequently wrote blog posts about machine learning fairness.
The ML fairness focused on racial disparity and gender disparity, and never looked at political bias. The one blog post Twitter published stated that right leaning accounts were favored. The data we obtained shows that to be completely false.
The documents show that Twitter flagged accounts as political misinformation for anyone who questioned election integrity, voter fraud, vaccine safety, covid-19, government organizations, and “partisan” media outlets.
There is a clear pattern of high-level officials at the Trust and Safety level collaborating with outside organizations as well as academic researchers to directly influence code and algorithms at Twitter. It is also important to note that due to the fact that the people writing code seemed to have the same political affiliation, no one seemed to find anything wrong with this activity.
No one internally asked questions because everyone was aligned with the mission to save democracy from misinformation. For all of the talk of diversity and inclusion, it is somewhat astounding that Twitter lacked any basic political diversity in high powered positions of people who could directly influence policy through code.
Twitter seemed to fundamentally believe that diversity and inclusion means exclusion at the highest levels. Data scientists were not empowered to question what they were being told by officials, and if they did, they risked being removed from a team.
As one source said, “Who am I anyway?”
This is a chilling expression of the lack of free speech that internal employees felt who were in fact arbiters of free speech on the platform.
High-level Trust and Safety executives viewed any discussion of voter fraud as highly problematic. Hundreds of thousands of accounts were potentially suspended and banned due to algorithmic bias. The high-profile accounts who discussed voter fraud were not held to the same rules. Therefore, we will never truly be able to measure public sentiment on trending topics, because a high majority of regular Twitter users were shadow banned from even discussing such topics.
Twitter knew this and that it would be a public relations disaster, which is why the high-profile accounts had specific flags on them to consult with PR and corporate communications before taking internal action. It is extremely important to note that regular Twitter users did not have any notations like this on their accounts.
By letting high-profile accounts discuss these topics without suspension, Twitter gave the public the illusion that they encouraged free speech. But the data behind the scenes shows the exact opposite.
In a blog post, Twitter stated, “When Twitter uses ML, it can impact hundreds of millions of tweets per day and sometimes, the way a system was designed to help could start to behave differently than was intended. These subtle shifts can then start to impact the people using Twitter.”
The smoking gun here is that this machine learning algorithm was designed to behave exactly as it was intended: to stifle free speech, to censor any questioning of voter suppression, and to shut down any conversation on the vaccine. That is not by accident; it was intentional by design. Twitter admits that ML can impact the behavior of users through subtle shifts. Based on the data I reviewed, the algorithm worked exactly as it was intended; to get people to behave differently, to stop questioning the election, to stop questioning the government, to trust the government, and to believe that vaccines are safe.
Who will be held for the harmful effects of the algorithmic decisions made by this team? Most likely, no one will. Musks’ only option is to start over and scrap everything that was created by the former ML team.
Data scientists play one of the most critical roles in social media content moderation at big tech companies today. What training are they receiving to make sure what they are being asked to do is legal, responsible, and politically inclusive? If they are being used as pawns by government agencies to push an agenda, are they legally liable if this goes to court? Ie- who is responsible- the one who told them what to monitor, or the one who did the implementation of the actual monitoring with ML?
A Twitter blog post states, “Leading this work is our ML Ethics, Transparency and Accountability (META) team: a dedicated group of engineers, researchers, and data scientists collaborating across the company to assess downstream or current unintentional harms in the algorithms we use and to help Twitter prioritize which issues to tackle first.”
This group never once looked at unintentional harms in the algorithms that could impact public health and safety. By suppressing any questioning of the vaccine as “safe,” Twitter also suppressed those who were vaccine injured. Did this team review the unintentional harm their algorithmic bias caused to the thousands of people around the world who are vaccine injured?
By creating an algorithm that suppressed conversation around vaccine safety, Twitter knowingly and intentionally harmed millions of users around the world who were denied access to public health information that showed the vaccines may in fact, not be safe. This was algorithmic bias led by design. This was intentional.
The META Team did not assess the unintentional harm of the algorithm they created and how that impacted thousands who are vaccine injured. They do not view this as harm. And fundamentally, we are back to the same issue yet again. What they view as harm is telling people the vaccine is not safe. They view questioning the election as harm. They view dissent towards the government as harm. Therefore, they will not objectively look at any of this, and will double down on making sure algorithms weed this content out. Therefore, any analysis they perform will be biased from the start.
Their definition of harm is not your definition of harm.
Combating hate speech with NLP or writing a new form of biased hate speech with NLP?
The Twitter META team stated that the public would have access to:
- “A gender and racial bias analysis of our image cropping (saliency) algorithm
- “A fairness assessment of our Home timeline recommendations across racial subgroups”
“We’re also building explainable ML solutions so you can better understand our algorithms, what informs them, and how they impact what you see on Twitter. Similarly, algorithmic choice will allow people to have more input and control in shaping what they want Twitter to be for them. We’re currently in the early stages of exploring this and will share more soon.”
The data I have access to was never publicly disclosed. No one can ‘better understand’ Twitters’ algorithm because they intentionally misled the public on the detection list and parameters of words they are scanning for. The public is not aware that the US government informs these algorithmic decisions, and they are certainly not aware of how they are impacted by them, let alone that it exists.
People do not have algorithmic choice. This is cagey language that intentionally misleads the public. Users lack any basic level of control in shaping their experience on Twitter.
Make no mistake: Twitter shapes your experience based on what it deems to be misinformation from the start. The illusion that you have any control in that process is nothing more than that: fake. Twitter will never be “what you want it to be for you” when an algorithm has already decided what is rue and what is false.
How can you know if AI is making the right decision when you don’t even know it is making decisions in the first place?
“The public plays a critical role in shaping Twitter and Responsible ML is no different. Public feedback is particularly important as we assess the fairness and equity of the automated systems we use. Better, more informed decisions are made when the people who use Twitter are part of the process, and we’re looking to create more opportunities for people to share their thoughts on how ML is used on Twitter.”
This is a definitive and outright lie. The public was not able to provide feedback because they don’t have any clue of the parameters running in the background, essentially rendering their feedback entirely useless. This is why so much of the conversation focuses on Yoel- instead of at the engineering or machine learning level. This is done by design to keep the public off track of what they really should be looking at in the first place. Twitter was not able to assess the fairness and equity of the automated systems they used because of their internal bias.
An outside, third-party entity must audit their systems, because Twitter has repeatedly shown they created machines that mirrored their personal and political bias, instead of the opposite. In their quest to create algorithmic “equality,” they created large scale inequality that benefited half the country and left the other half shadow banned. This was not by accident. It was done by design. It was an intentional choice that numerous layers signed off on- therefore making sure that no one could be held responsible for it.
People have no clue how machine learning is being used at Twitter. When sharing this data, people don’t even know what they are looking at or reading. So, to assert that they are looking for more opportunities for people to share how Machine Learning is used on Twitter was another deceptive statement from Twitter.
Responsible AI should be renamed “Irresponsible AI”
Twitter’s Former Head of ML Ethics, Transparency, and Accountability was led by Rumman Chowdhury. In recent months, Chowdhury has openly posted her disdain for conservatives and Musk on Mastodon.
How can someone in charge of algorithmic ethics be entrusted with this role (at any tech company) when they are not even hiding their disdain for half the country? Chowdhury and colleagues like her in data science are responsible for creating the underlying skeleton of Machine Learning products in Silicon Valley.
Why are we hiring people for “responsible AI” that are openly irresponsible with their own social media posts and political views?
They are not hiding it. It is there for everyone to see in plain sight.
If my personal social media shows political bias towards Democrats, should I be hired for algorithmic bias? No. Neutrality is essential in this role at the highest level.
In an interview with another media outlet, Chowdhury stated, “People need structure and understanding of where the guidelines are; otherwise, they’re going to drive off the road. You need to know where the lines are, and then you’re able to do really great things and build really interesting models.”
Here, Chowdhury openly admits that guidelines existed at Twitter. However, she fails to leave out what they actually are.
These influential AI ethics researchers and data scientists work at all of the top companies in Silicon Valley. A quick review of their former employers reveals big names like Meta, Pinterest, McKinsey, Buzzfeed, WeWork, Google, Microsoft, Comcast.
According to Protocol, Twitter’s former AI ethics director is still engaged in an ongoing legal battle with the CEO of the startup she founded.
“If anything, the lawsuit is an unfortunate distraction for a community and emerging tech sector that aims to integrate much-needed ethical principles of accountability, transparency, trust and responsibility into a largely unaccountable and freewheeling AI industry.”
“Beyond user choice and public transparency, Chowdhury’s goal is to create a system of rules and assessments that function like government over the models: a system that could prevent harms from occurring.”
Chowdhury and colleagues are not hiding that they want the AI they create to function like a new form of government that rules over a class of people they disdain. The more power high-powered data scientists like Chowdhury have at any tech company- the less power you have as a citizen to stop this from reoccurring at scale at any company they work at next.
Because of the irresponsible AI deployed due to personal political bias, the algorithms amplify misinformation that it is being trained on from government agencies.
TL;DR: The algorithms are actually deamplifying and suppressing real information that the third-party agencies are stating shouldn’t be shared and instead should be re-classified as disinformation.
In a media interview with another outlet, Chowdhury stated, “However objective we may intend our technology to be, it is ultimately influenced by the people who build it and the data that feeds it. Technologists do not define the objective functions behind AI independent of social context. Data is not objective, is it reflective of pre-existing social and cultural biases. In practice, AI can be a method of perpetuating bias, leading to unintended negative consequences and inequitable outcomes.”
Chowdhury and colleagues did not mitigate algorithmic harms- they enhanced them to their own political preferences with total carte blanche.
A reply to a tweet that Chowdhury posted. Unable to see the original tweet as the account is locked.

In my opinion, the former data scientists on the META team at Twitter hired for “responsible AI” used AI in the most irresponsible way possible.
AI was used to detect for MyPillow instead of child pornography.
AI could have been used to help people. Instead, it was gravely misused to hurt children. How did it hurt children? Because it wasn’t being effectively used to spot and remove CSE content at scale. Instead, resources were allocated to detect for MyPillow.
If you train AI to detect political “misinformation,” you can train AI to detect CSE imagery at scale. The lack of AI resources utilized against this problem ultimately meant that the imagery stayed up far longer than it should have. That hurts children.
That being said, the collective blame should not be placed on the individual data scientists- but rather- the managers who routinely ignored their complaints to properly allocate resources to address this issue- as evidenced by the internal Twitter screenshots below, which prove that these requests to staff engineers for CSE were raised in April 2021.
In their expert opinion, former Twitter data scientists stated they didn’t have enough people monitoring CSE in leaked screenshots.
🚨BREAKING:
In a private WhatsApp conversation on 12/9/2022, Data Scientists at Twitter stated they didn’t have enough people monitoring CSE.
In April 2021, leadership was warned internally about lack of CSE support. #RubyFiles pic.twitter.com/Goy06zlduc
— Kristen Ruby (@sparklingruby) January 1, 2023
OPINION:
Is Elon Musk saving speech or is he programming the future of speech with AI?
Can speech ever truly be free when algorithms are involved?
Artificial Intelligence is a force for good when it is used the right way. The intention of this article is not to scare people, but rather, to educate people on how it works, and the implications AI has on the future of social media content moderation.
Furthermore, it is important to understand that many of the words shared in this reporting were not banned in isolation. Rather, they were flagged in a data corpus as possible US political misinformation.
I have many questions to further explore, including:
- Who determined what words were included in the corpus and why?
- Who is the ultimate arbiter of US information?
- Should the data corpus include equal misinformation for both conservatives and democrats?
How can a machine learning algorithm censor ordinary Twitter accounts?
The issue of the moment is Musk’s handling of Twitter, but the issues at stake are significantly larger.
Critical content moderation decisions are made by algorithmic bias and not human moderation. Instead of blaming a person, perhaps you should be blaming a bot.
It all goes back to training. What was the input? What was responsible for the word list of the input? What were the parameters? And how often was it retrained?
There has been very little discussion of this. Instead, the conversations are misguided, shouting esoteric terms like free speech, while lacking any education of the inner workings behind what that actually means from a technical level. This ultimately leads to misinformation.
If you do not have information, you are left with misinformation, because you do not have the full picture to make an accurate determination or assessment of how things work behind the scenes.
For the past 15 years, I have reported that many decisions made by big tech companies were being done with political algorithmic bias and little to no human moderation. At the time, that was a hypothesis, but my recent research has further enforced my view that it was correct.
But the thing about bias is that even the people who code may be biased to their own bias. This is relevant to the discussion. Even the people we trust for our own trust and safety may be biased by what trust and safety even means. Who are we collectively determining to guide our safety as a nation? Are these truly the right people for the job? If not, who is?
For example, imagine someone is racist. If you ask that person if they are racist, they will say they are not. Similarly, if you ask someone who may have political bias if they engaged in censorship, they will say no. They really believe that they did not, despite data showing a different story. This is pertinent to the discussion.
So much of the reporting has focused on the malice of people who previously worked at Twitter. But almost none of it is on the fact that many of these former Twitter executives really believed they were on a mission to make the world a better place. This is akin to someone who shoots up a school and then posts a manifesto on why they did it. They believed in the mission. Every action they took was towards that mission. And that mission was meant to protect you and the future of humanity.
You are looking for people to admit to something that they do not believe they did wrong. In fact, they believe they were saving the world by what they were doing. This is why a discussion of censorship and political bias at Twitter is so hard to cover, because no one is really looking at the underlying belief system that guides the decision-making process among c-suite leadership.
A failed media system
On paper, the source and I objectively have nothing in common. The source has stated they are on the left. I have publicly been aligned with more right leaning media. And yet- when it comes to data- none of these things should matter. Except they do. And this is exactly the problem.
When political polarization erodes into the system and institutions to make analytical decisions, we are a failed nation state. When political polarization keeps us so polarized that someone on the right won’t even speak to someone on the left, we have a failed media system. In essence, we are recreating the very bias that we are blaming algorithms for.
In the search for truth, and to find out what guano meant, I found out much more than I ever anticipated. And had I not spoken to this person because of political bias, we would have missed the real story here- hiding in plain sight.
As a nation, we are missing out on information that needs to be reported because people won’t talk to each other. The truth is, this person is left-leaning and fundamentally agrees with the decisions made during their time at Twitter. They are proud of that work. In my search for guano, and in my series of hundreds of follow up questions, this person may have been forced to confront their own possible bias that was possibly overlooked. But I also was forced to confront my own, too.
As I continue to watch the media circus feast off of Musk’s every tweet, I cannot help but think that we will never truly know the full story of what happened at Twitter. That is not Musk’s fault. It is your fault. It Is my fault. It is everyone’s fault. Why? Because this hyper polarization that plays out on Twitter daily keeps people from being their true authentic selves. They have to guard the data from the enemy- you- the one on the other side. It is only after breaking down that barrier that you can see the search for truth and data should bind us all. It shouldn’t be political. But just because it should- doesn’t mean it does.
Nothing about data science should be political. And yet it is. People are so far in their positions- as the source stated- that to veer from the position would be isolating themselves from Musk- and from their peers- on the right.
On the left, agreeing with any of Musk’s decisions would be seen as the cardinal sin of dishonesty to the Mastodon crowd. This is a lose-lose situation for all involved. I am left wondering what the end game is.
Why are we all so obsessed with Twitter? What does Twitter mean to you? And why are we sad if it fails? What does that mean about us? Is Musk our only hope for “free speech” and the fight against big tech political tyranny? If he fails, does that mean we have all collectively failed? Are we fighting so hard because we know this is a losing battle? Have we collectively put our hopes and dreams into one person- with expectations that are larger than what any one person could do? Do we expect more from Musk than we expect of ourselves?
Is Elon Musk’s time best spent policing Twitter drama? And more importantly, is my time best spent following it daily and reporting on it? I don’t think his time is best spent on this, and I don’t think mine is either. But we are so engaged in this reality TV show that we can’t pull the plug because that would mean returning to our lives, and the mundaneness that comes with it.
Are our hopes wrapped up in one person? And is our collective sense of failure wrapped up in one man, instead of in ourselves? I don’t think Elon Musk can save us. But I do think you can save yourself with the decisions you make, the media you consume, and the information you choose to educate yourself with. Knowledge is power. And one thing is clear.
The more time we spend on Twitter battling the other side, the less time we spend learning how to advance ourselves to become the next Elon Musk. Stop being a daily active user of Twitter, Meta, Reddit, Mastodon, or any other big tech company, and start being a daily active user and participant in your own life.
You can either be part of the dataset, or make your own data. Do you want to be trained in someone else’s model, or do you want to make your own model? Fine tune your life instead of fine tuning someone else’s platform. In the end, you are a user, not an owner.
The million-dollar opportunity in front of you is not whether Twitter fails or succeeds, but rather, whether you fail or succeed in the next industrial revolution of AI.
Is this the end of centralized social media? Or is it the beginning of a new chapter of private, gated social media?
Having reported on social media for years, I could certainly come out and say, “See? I told you so. I was right.” But I know the apologies will never come. And I don’t believe anything will happen legally from any of these former actions. But I do believe that AI is going to fundamentally transform our world and how we communicate. I have spent the past two years moving in this direction, and I am grateful to have worked with and learned from some of the best in the AI space. Knowledge that isn’t shared is wasted.
My core concern is that we have reached a point in social media where people are speaking in two different languages, and those who understand the language of data can far surpass those who don’t. This can also directly influence the reporting of it based on the fact that people are simply not reporting on something they don’t know to ask. While this is a competitive advantage for data scientists, it is terrible for the average Twitter user who doesn’t grasp the implications of the decisions made behind the scenes.
We can’t possibly have an intellectually honest conversation about free speech if you don’t understand how AI/ML impacts what speech is allowed, and what speech is suppressed. I watch pundits every day on TV (yes, even Republicans) rant and rave about free speech and censorship, lacking the basic knowledge of what AI even means. This is dangerous, careless, and reckless. They are inadvertently spreading further misinformation into the media ecosystem.
People like to complain that Elon Musk is a billionaire and therefore he has some competitive advantage. Elon Musk’s primary competitive advantage is not his wealth- it is his knowledge. Fundamentally, if you don’t understand that, then you aren’t even in the game. The good news is that you have the option and ability to change that. You can educate yourself with freely available information and courses on all of these things so that your opinion holds weight on these topics. We are entering a new era, where free speech really means programmed speech.
The question is: who determines who programs it and what words and phrases are programmed?
Dangerous AI: How AI can be misused as a powerful form of censorship
Free speech is dead. Not in the literal sense, but in the AI sense. Detections and parameters will dictate the future of free speech. There are two groups of people: those that get this and those that don’t. And if you are in the group that doesn’t get it, the first group is banking on that.
You can hem and haw all you want about being suspended, but most of the time, you aren’t even being suspended by a human being.
Elevate yourself to elevate the conversation.
Only then can we have a real conversation about the future of social media and free speech on Twitter and beyond. Until then, we have old speech, and new, programmed, AI based text classification.
The nuance of free speech, AI, and content moderation
Declarative statements that Twitter was either all good or all bad are simply not accurate. Twitter was comprised of thousands of people. Those people made individual decisions that other people executed, and many people seem to not even know about due to siloed information.
People are complex. Systems are complex. Algorithms are complex.
Having personally interacted with several people on the community management side of Twitter Spaces, I do not believe every employee there was bad or had malicious intent. In fact, one of them worked extremely hard to combat women being harassed on social media, despite this going way outside of his scope of work.
While it is easy to put a political view on this, it is harder to objectively look at what and where things went wrong. Many of these social media systemic AI and content moderation issues are not unique to Twitter. They are happening at every single social media company. That Twitter finds itself in the spotlight for this right now is unique- but next year, you can fill in the blank with another social media company that will be under the same level of scrutiny.
I am not sharing this to say I was right and you are wrong. It is not even to get an apology from all of the people who called me a conspiracy theorist when I explicitly stated that AI was driving many content moderation mishaps on social media platforms, particularly among conservative public figures. But rather, it is to give people access to information that will help them see a more complete picture. It is up to you to determine what you want to do with that information.
Part of the problem with the reporting on social media is that it has become so politicized that everyone has baked in editorialized judgment and bias with the reporting. How can we report on algorithmic bias if the media is deploying their own bias in their coverage? If we can’t objectively separate our personal bias from what we are covering, how can we expect others to do the same? If we want to be held to the same standards, that starts with better journalism.
The average Twitter user who gets banned or suspended does not have millions of followers. They do not have high-profile marks on their accounts monitored by public relations or trust and safety executives. Some of the current narrative on Twitter actually does a disservice to the regular Twitter user who just wants to know why they can’t use the platform and what they did wrong.
Ultimately, the focus needs to be on the regular users, stripped from the polarization of the technology. This is actually what they care about. They want to know why they were banned- not why Trump was.
Yes, many of you want to know why Trump was- but the point is that there is an entire swath of the population that just wants to use a platform without being dragged into the constant political weaponization of social media and big tech.
I fear that in our rigor to uncover the truth, we have lost track of the truth that some people just want to connect with others and use social media how it was originally intended.
Our focus must be on the future. Not who was wrong, how they wronged us, and why they need to suffer and pay. Forgiveness is important in this process. We must rise above and come to the challenge. What does that mean? Encouraging political diversity in data science.
Teaching people how machine learning works, and how algorithms can impact social media content moderation decisions. Focusing on the regular platform user instead of the platform influencer. Not using private user data to make headlines by potentially sharing PII and leaving more questions than answers.
Leadership means leading people somewhere. The recent chaos surrounding the future of Twitter has bled into the reporting of it. Additionally, the recent suspensions of journalists have led many journalists to wonder if they should switch beats and stop covering this. When forced to decide if they want to keep covering Musk and risk losing platform access or not cover Musk and stay on the platform, many are deciding it’s not worth the battle.
Twitter is a leading social media and technology company. And yet, we have a critical problem in the media. Those who are covering Musk are more focused on his policies than with the actual technology being deployed that enables the policies. Part of the reason for this is that when he does discuss it, they have no idea what he is talking about. As far as I am concerned, that is an epic failure on the part of the media.
If you can’t understand what Musk is saying about basic engineering decisions or tech stack questions, then how can you report on this beat? This is akin to saying a White House/ US political reporter can’t ask policy questions because their background is in entertainment. Why do we have people covering a beat who lack basic engineering knowledge? This is a social media company. How can we truly evaluate Twitter against competitors if we can’t ask basic technical questions to assess true competitive advantage?
Ultimately, I don’t believe people are going to get the justice they are looking for regarding transparency on how decisions were made, and the potential political consequences of those decisions. Why? Because data is useless if you don’t understand how to read the data.
Twitter is not a good source for long-form journalism or investigative reporting. My threads created even more confusion, because the first thread wasn’t connected to the other, so people lacked proper context of what I was even talking about in the first place. We need to slow down to speed up. We are all racing towards something..I am just not sure what. Taking the time to explore the data is just as important as releasing the data itself.
In questioning my reporting, some of you asked: Why her?
Why not me? And why not you?
Do not rely on any one person to find the answers you are looking for. The truth is inside of you and not only the information you choose to consume. If you are not happy with the answers you are getting, start doing the work to discover the answers by going directly to the source. For information of this magnitude, it is a mistake for one or two people to drive a narrative. It would be a mistake for even me to drive the narrative. Public access to information is required.
Giving information to a few people continues to filter information through a narrative that is tightly controlled. Whose narrative is right? I don’t know anymore. I fear the speed of information coming at us is harming our ability to process what we are reading. The drive to rapidly tweet at warp speed acceleration is leading to a deceleration of analysis and insight.
Twitter Suspensions & AI
Recently, a slew of right-leaning accounts on Twitter have been suspended and locked. It also appears like mistakes are being made- ie- tweets are being flagged for violating sharing personal information and intimate videos without permission- yet the tweet is of a flag. Why is this happening? It is unclear. Perhaps the image encoder decided it was defamatory? Or maybe it misfired. All anyone can do is make an educated guess at what is happening without reviewing the backend date.
One thing is clear: if the data is not retrained, cleaned, and updated, this will keep happening. Free speech on Twitter will never happen with a contaminated dataset running in the background. If you believe this myth, then you don’t truly understand that free speech is directly tied to programming, coding, machine learning and AI. It doesn’t matter what Elon says. It doesn’t matter what I say. It does not matter what anyone says.
If the parameters for detection are coded with built in political bias, the machine will keep doing what it was trained to do. It will not “learn” to go in a new direction because it is not trained to.
Unfortunately, most people do not understand the role of AI in content moderation when discussing free speech on social media platforms. This is the real problem.
“On any given day, users post more than 500 million Tweets—5,700 Tweets per second.” – Supreme Court filing
The conspiracy theories floating around that rogue employees are doing this at Twitter is bizarre. This continues to happen because Musk is not addressing the elephant in the room: the people who created this monster of a machine no longer work there.
They went to great lengths to make sure their work was protected, and that it would not be easy to dismantle the model. They know that training a new model and scrapping this one costs time, resources, and extensive funds to start over again- all things Musk has doubled down on not wanting to do.
An expert in the field could make sense of all of this- provided they had access to it. According to the source, who wishes to remain anonymous, “so many people left that they might not even know where to look for it or how to get permission to access it.”
Simply put: this algorithm is still working in the background, regardless of the fact that they no longer work at Twitter. They don’t need backend access to make sure the model keeps working, even if they are on longer employed by the company.
It takes time to get an effective model, and that is not something Musk has. According to the source, “no one else there knows what is even in the models. All of us are gone.”
This begs the question: does Musk know? Who does know? And has he looked at it? The only way to fix contaminated data is to retrain the model or scrap it.
Twitter was not transparent with training material, who influenced word lists for ML algorithms, what words were being detected, and how ML scored users tweets algorithmically. However, this issue has still not been addressed. Musk must be transparent about how new policies are created, and what word lists are currently being used for training sets, and what third-party organizations are involved in both the creation and oversight of the training material.
In the upcoming year, I hope to focus on creating a bipartisan group of data scientists, machine learning experts, content moderators, and trust and safety professionals who can come together to educate the public on how all of this works. It is simply too complicated to explain on Twitter, and people deserve answers to the questions they are seeking. If you are interested in helping people understand, please do reach out.
Some of you have reached out to me to ask if your name was in the data. I do not want to share PII, but I will state that the one name I saw repeatedly in every dataset I have access to is Dinesh D’Souza. Based on the data, it is clear that Twitter viewed Mr. D’Souza and the movie he produced as a great threat and form of political misinformation. AI, NLP & ML was heavily used by Twitter to make sure D’Souza tweets were flagged.
AI SOLUTIONS & RECOMMENDATIONS
Emerging challenges in AI & ML at Twitter involve solutions in the following three areas:
- Technical Solutions
- Policy Solutions
- Product Solutions
How can you resolve the potential harmful effects of the algorithmic decisions made by the former Twitter ML team?
- Create a bipartisan responsible machine learning council. The interdisciplinary group will be comprised of people from both political parties, not just one.
- Prominently display Academic Research disclosures. Are there any conflicts of interests with the academic researchers? If so, this must be clearly disclosed, and not hidden or buried in a blog post that no one reads.
- Update third-party affiliation disclaimers. Clearly define who the outside government agencies are that directly influence Trust and Safety decisions at Twitter. The public should not need to do Twitter Files investigative journalism to access this baseline information.
- Gut the code. The current AI model at Twitter is contaminated. Retraining that model will delay the inevitable outcome, which is that the model needs to be scrapped.
- Hire a neutral party to conduct quarterly algorithmic assessments. Engage a third-party consulting firm to assess the downstream or current unintentional harms in the algorithms deployed at Twitter. Algorithmic assessment audits must be conducted by neutral investigators.
- Review the reviewers. Create an oversight board to review Twitters application of ML. No one is reviewing the reviewers. This is a problem.
How is machine learning currently used at Twitter under Elon Musk?
The answer to this question should not be a black box mystery. Clearly state the detection and parameter list. What actions are judged as positive? What actions are judged as negative?
If Musk truly wants to build in public, that also means sharing in public.
Building in public also means taking down in public, too.
Musk is headed for a catastrophic PR disaster if he has promised free speech but the backend hasn’t changed. The public can state that he materially misrepresented platform terms and promises, and this can lead to a mass exodus of users if he doesn’t deliver on the stated mission.
You can’t have free speech while you are still actively deploying contaminated code that was built to censor. From a PR perspective, this crisis could be the true downfall of his reputation if he does not let people see what is taking place on the backend currently vs. previously.
Nothing in The Twitter Files comes close to the raw data I have shared. Posting Slack screenshots and private emails is not remotely the same as releasing raw data to the public. If anything, it is just another layer of censorship by selectively choosing what the public can see.
Free speech entails seeing all speech, and the parameters currently deployed to monitor speech on Twitter. None of that is happening. Until it does, any free speech claims are just rebranded with right-wing wrapping paper.
If you want the public to believe that speech is free:
- Don’t charge them for it.
- Show them the current list of stop words and n-grams.
- Release all files instead of selectively censoring files through a group of approved journalists.
How do you know the machine learning systems are making the right call? You don’t. Why? Because you don’t even know what is in them or when they were last retrained.
CONCLUSION
Artificial Intelligence is shaping the future of product development and social media content moderation.
The Future of the Social Media landscape will be largely influenced by Machine Learning.
It will be controlled by three primary factors:
- Proprietary data
- Fine tuning the data
- Amassing large volumes of proprietary data to create a neural network
Machine Learning, Elon Musk, and the Future of Twitter
Why do you think Elon Musk was interested in acquiring Twitter?
Elon Musk acquired Twitter, which makes one wonder why he paid the price that he did. The most viable explanation is that he bought Twitter for the large source of proprietary social media training data that exists: your tweets.
With the rise of social audio features like Twitter Spaces, that data becomes even more valuable when you factor in speech-to-text for natural language processing.
The platform in and of itself was not valuable from a monetary perspective, and by all measures, was considered a failing business. But by acquiring Twitter, he bought increased power, access, and influence.
Twitter’s machine learning models influence everything from global elections to information control during a pandemic. These are powerful levers of communication as a form of warfare during a digital arms race.
While Musk fundamentally lacks controls of the models in the short term, he will ultimately gain control of those models in the long term. And when that happens, there is no telling what comes next.
One thing is clear; he appears to have a vested interest in not sharing any files pertaining to the underlying training dataset, corpus, or n-gram lists that powered the models.
Machine Learning was weaponized by Twitter to dismantle the core tenants of free speech in America.
A platform that does not show how free speech was dismantled with Machine Learning is ultimately a platform that is safeguarding ML as their competitive advantage.
The Ruby Files shows how Machine Learning was used by Twitter in powerful ways, ranging from election integrity to censorship of health information.
Musk is not interested in showing the evidentiary trail of how that happened. Fundamentally, there is a difference between saying something happened, and showing how it happened.
The Ruby Files is the first and only look at the machine that ran Twitter. Nothing else comes close to this data. Musk knows it. I know it. People are starting to understand.
This is not a story Musk wants shared because it would not only implicate him in the ML crimes that were committed, but it would also expose what he perceives to be his greatest weapon at Twitter: Machine Learning.
He knows the machine learning models he acquired were flawed, so much so that his lawyer cited the models built on stolen IP to try to back out of the deal. But he clearly sees opportunity.
Revealing the inner workings of the model would ultimately reveal the real story: that Twitter will never truly be a free speech platform.
Not because of Elon Musk- but because AI is not neutral.
Releasing past, current, and future machine learning training documents would unravel the narrative that Twitter is the only free speech social media platform. Something has to be positive. Something has to be negative. Behavior has to be reinforced.
Elon Musk will not reveal the details of any of it because he knows it would ultimately reveal the truth: that no social media platform powered by machine learning will ever truly be free.
Free speech comes with a price.
For consumers, that price often comes at their expense by being used for training data, non-consensual machine learning experiments, and information warfare as a form of leverage, power, and control.
We are at a turning point in history, where natural language processing can be used to wipe out entire categories of language.
This is not free speech. If anything, it is invisible speech. An NLP-powered war would be silent, because you would never even know it happened.
The Ruby Files reveal that over the past two years, Twitter weaponized Machine Learning against American citizens.
While the current media focus is on the danger of OpenAI, we don’t need to wait to see what happens next.
A close study of The Ruby Files will reveal that this was not just an AI pilot that existed over the past two years, but rather, it was in full-fledged production.
The weaponization of OpenAI ChatGPT is a distraction from the real issue at hand: not how AI could be used against you, but that it already was.
UPDATE: Since the initial publication of this article, Twitter released parts of its recommendation algorithm. My thoughts on this are below:
What algorithm does Twitter use?
Twitter trains and deploys numerous machine learning models. There is no single algorithm that guides the system. Open sourcing the Twitter algorithm without sharing information on the model weights or terms that indicate toxicity or misinformation is problematic for a number of reasons.
The models cannot be inspected in the same way that the code can be inspected on GitHub if the most critical machine learning information is intentionally left out of the “open source” reveal. This is a way to keep everything close sourced, while pretending it is open source.
Any machine learning expert will tell you that without this information, everything is still, in fact, closed sourced. We are not any closer to understanding how Twitter uses Machine Learning since Musk took over. Engineers have alluded to changes, but it is not clear what if any changes have been made.
Revealing a recommendation algorithm does not help anyone understand how Twitter uses AI to make decisions in the age of Machine Learning.
As I have said for months, the models are more critical than the algorithm.
- What are the models trained to do?
- How many models are currently running at Twitter?
- Is the political misinformation model still running?
- How often are the models retrained?
- What type of behavior is reinforced on Twitter?
- What new words indicate misinformation in the models since the acquisition?
- Have any of the words in The Ruby Files reporting been removed from the model as indicators of misinformation? If so, which ones?
- What decision making process guides the models and who is responsible for training the models?
- How often are the models audited by outside, third-party organizations?
- Can users opt out of their content being used in training data? If so, how?
- What filters are applied?
- How is Natural Language Processing (NLP) currently used on Twitter?
- What are the current safety labels?
- What are the labels for toxicity?
The real visibility filtering happens in the Machine Learning models that run the system. This content is automatically flagged as misinformation without ever being reported. Musk did not reveal any information on what phrases are being filtered as misinformation in the new models. Sharing an algorithm on “visibility filtering” without showing *what* is being filtered from actually being visible is entirely meaningless. It is only meaningful to someone who doesn’t understand Machine Learning.
Twitter’s Recommendation Algorithm
What did Twitter fail to release?
Selectively disclosing information while leaving out the most critical information. Twitter did not release trained model data or model weights.
- Model weights
- Trained model data
- Training set
- Updated n-gram list for disinformation
X’s approach to The Digital Services Act:
Automated Content Governance
The AI infrastructure Musk is building is critical for automated AI content moderation driven by machine learning.
To comply with The Digital Services Act, X must be rigorous about content enforcement. Elon Musk can do this by increasing headcount or increasing automated content governance. It is clear to me that he is choosing the latter.
Twitter is rapidly hiring staff to adhere to the new strict guidelines set by The DSA. While Facebook has hired over 1,000 employees to adhere to The DSA, Twitter still has a long way to go.
AI Content Moderation Risks
Twitter will rely on a combination of AI and machine learning to adhere to the new DSA standards. However, when it comes to content moderation, relying on technology over human intervention does not come without risks.
The ultimate risk is that AI will make the wrong judgment call and may over-optimize when it comes to critical enforcement decisions. As we learned in The Ruby Files, content moderation mistakes can often come at the expense of users. The AI content moderation mistakes can result in suspension or even account termination without warning and with little recourse.
DATA SCIENTIST REVIEW/FEEDBACK ON THIS ARTICLE AND THE DATA SHARED:
Data Scientist 1:
I was recently interviewed in a Twitter Space. An experienced data scientist specializing in NLP sent me an email stating the following after listening to my Twitter Space on my reporting to date:
“I am really tired of the perspective that the workers (in this case “data scientists”) don’t know what they are doing. They absolutely know what their models are being applied to. We don’t have general AI yet, nor are we even close. This is how the models are evaluated – with feedback on real data.
The thinking of many is a bit outdated, too. NLP has long moved from keywords to vector models. The data scientists absolutely know and shouldn’t be given slack and they are certainly monitoring the results of their models. Who wouldn’t do that for the most talked about issues of the time?
The teams on the right are so far behind. There is a reason that Cambridge Analytica employed people who were on the left. But there really is no upside for being involved in tech on the right. The Pinterest whistleblower is probably forever going to be relegated to working at places like Project Veritas and making far less than he used to, and will only find boutique employment if he goes back to tech.
It seems that many Millennials, especially tech workers, really have trouble believing that some people act maliciously or unfairly. I can see the frustration with the lack of urgency that others feel about this.”
“That sounds exactly how I would expect an enterprise machine learning pipeline to work.”
“We break the words into n-grams, we lemmatize, we tokenize.”
“This is the pre-processing stage. The whole point of this is making things easy to compare meaningfully. Vectors are easy to compare since that is an arithmetic operation. So, pipelines will convert things from words to vectors. When we put things into a vector representation, we call it an embedding. The rest of this seems exactly how I described. Where H COMP would be the annotators/labelers.”
As you can imagine, abuse and the potential for abuse is wide in that field in regard to NLP.
Think about all of the live generative capabilities of ChatGPT and then imagine the analytical capabilities that are possible over long periods of time. This is what the companies are able to work with. Keep in mind, the publicly released ChatGPT-3 is already months old. ChatGPT-4 is a completely different level.
These two processes are very different, and that the generative case is much harder than the analytic case. So, if someone is impressed with ChatGPT-3 and what it can do it nearly real-time, imagine the capabilities of a system that has all the time in the world to try to connect historical data. There is no doubt that Twitter (and whoever else was calling the shots about the data) does that.
While everyone is justifiably wowed by ChatGPT, the ability to analyze people and tweets are far more sophisticated, largely because we have been doing this for longer.
Word vectors and word embeddings are the basis of how modern NLP tools operate. For someone who is not used to linear algebra, it can be a bit hard to intuit. But the big picture is that words are mapped to points in a high-dimensional vector space (you may see references to Word2Vec).
In these higher dimensional spaces, similar words and n-grams cluster together. This is how topics are modeled. You are lucky you got specific words, because nowadays, concepts are generally contiguous regions in a carefully chosen higher-dimensional space.
Here is a visual example of how “word embeddings” work. The picture below shows two different 2-dimensional slices of a much higher dimensional space. In the first box, you can see how the blue vector shows a female direction. In the second box, you can see that the red vector shows something being made into a plural.
So, imagine doing this for users too. They are certainly classifying users because this is essential for spam detection and recommendations. I have done plenty of work with recommender systems and graph databases in the past.
With vector search, you can cluster things beyond just text. Once you have the appropriate transformers, you can map things such as images, sound, video, and text to the same space.
So, these tools of censorship are truly all-encompassing of media.
Every click you make is going into the model.
Actually, you don’t even need to click. Because the amount of time you spend looking at a post is yet another model factor.
These models are additive, so tech companies make many of them and then figure out which ones are most predictive per user (see “multi-arm bandits).”
Regarding the other dataset, those look like annotations. Typically, a person creates the label. They take a few examples of items that fit the label and then probably do the following:
- Send some labels and examples to an annotation team so they can label a few thousand examples. These are often outsourced to places like the Philippines, Latin America (DignifAi), Eastern Europe (Humans in the Loop), where people get paid a few cents for each label.
- These annotated data are used to train models.
- Data scientists monitor the output of the models and adjust them based on the results.
We are nowhere near doing this whole process without humans in the loop.
The screenshots look like they show content that has been judged by their models to fit in one of these categories.
They must have had some sort of situation room. As you can see, these labels are being made for very ephemeral stories. There is certainly someone or a team of people monitoring and creating these. They sometimes hide behind the scale to excuse inaction, but clearly they are able to pay attention to many little events.
Data Scientist 2:
A senior data scientist specializing in NLP stated the following after reviewing the data:
“I agree with Elon Musk when he described Twitter’s AI as primitive. To give one example of why that’s important, Twitter’s AI (in your dataset) treats all forms of vote (voting, voted, etc.) as the same. It ignores tense.
But pretty much all NLP since 2013 uses Word Embeddings (Word2Vec’s breakthrough), which is why LLMs can handle tenses correctly.
Twitter’s AI doesn’t appear to know the difference between encouraging someone to do something, saying someone else did something, etc.
In November 2020, talking about voter fraud in the present tense and talking about it in the past tense could be a big difference.
A lot of the most dangerous misinformation is about something that is happening or will soon happen.
Claiming the 2020 election was stolen is wrong, but appears to be less dangerous than claiming the 2024 election will be stolen.
This is all my personal opinion, especially about what is more or less dangerous.
But removing basic info, such as tense, means the AI has a lot less context compared to modern Large Language Models.
I only have the examples you provided in the article, but they do show the problem with the n-gram approach, compared to Neural Networks.
A lot of these n-grams are probably statistical noise:
“America and” doesn’t mean anything.
“Deep” cannot possibly be a useful n-gram. It will pick up “Deep Learning” and “Rollin in the Deep” and lots of other things. A NN with Long-Short Term Memory would be able to put the word “Deep” in context.”
The n-grams reflect lack of sophistication. These look like rules. The good news and bad news about n-grams is that it’s relatively easy to tell why a tweet got flagged compared to a NN-based system.
Data Scientist 3:
After reviewing the data, one Data Scientist felt the supervised model at Twitter was not sophisticated.
“I finished the article. It’s very comprehensive. Overall, I agree with the former employee that they used their best judgement in an area that is somewhat subjective.
That being said, the n-gram approach is very manual and ends up requiring people to make decisions about whether to include “MyPillow” or “magat”.
A neural network-based approach would still need people to decide what is and isn’t misinfo, but there would be more consistency in terms of what gets flagged for review.
The n-gram approach risks a feedback loop where Twitter flags Tweets with “MyPillow” for review, finds misinfo and then misses leftist misinfo entirely.
But I haven’t seen examples of leftist misinfo that’s made it through the filter, so I have no evidence that actually happened. What I mean is that there is no evidence that Twitter missed major sources of disinfo on the left.
The supervised algorithm will miss leftist disinfo if it isn’t programmed to look for it. It only looks for terms that someone has put in.
There are some leftist terms, such as “magat,” which is used to insult Trump supporters. But there could be entire areas that are missed because Twitter’s Trust and Safety team isn’t looking for them.
The more manual the process is, the more likely it is to reflect the biases of the humans implementing it.
Because the vast majority of n-grams are right-coded, we don’t really know what was missed on the left.
Overall, it does show a very manual process compared to the state-of-the-art technology today.”
Data Scientist 4:
Anonymous physicist quantitative researcher with a Ph.D in theoretical physics from Yale.
“If you train with a biased corpus, it will pick out a similar meaning. It all depends on how you train it. From the data you included in the article, it does seem they are training on terms like election fraud. If you train on it like this, of course you will get particular leaning results that reflect the bias of those who trained the model. The data you shared is evidence of this.
It doesn’t matter whether it’s AI or ML- it’s statistical probability- distribution/ skewed concentration and you will have bias. The whole neural net is dependent on bias and weights- coefficients that define neural networks have to be biased. The question is- turning on bias in which way? They shouldn’t have this filter in the first place whether it is left or right.
If you want a freedom of speech platform, then you shouldn’t filter it at all. The only thing you need to filter is child pornography or sex/human trafficking content to detect that with AI. Other than that, you should let it go or detect the bots. That is a different story. It doesn’t matter which way they are leaning if they are bots on the platform.
In my professional opinion, the data shows there was algorithmic political bias. If they are doing this word censoring- it is censoring. Why do you want to train this model at all for this? I don’t care whether it is left or right leaning.
If Twitter does have these keywords or forbidden words (election fraud, Maga, American flag emoji), these are forms of censorship through machine learning. I don’t think our country is built on this principle.
It doesn’t matter which way you do it. You can use a pen and pencil, human mind, or machine learning- all are tools. It is all probabilistic distribution and statistics- a knife, gun, or ML. It’s censorship.
Regarding what Twitter did and what this dataset shows- it is censoring- plain and simple. It is so basic. How could anyone even question this?
The very existence of this list of dirty words is an indictment of using AI to censor. The data is staring in your face. If data scientists think this is the right thing to do to establish a police state in service of the greater good, then you are proud to be the Gestapo. It is the exact parallel to China.
AI will destroy freedom of speech if it is used as a political weapon. People will then censor themselves and find clever ways of reconstructing sentences. This is what is currently happening in China.
Did they have a list of words to train on? It is plain and simple. The machine didn’t say- ignore the list of words or find the antonym to the words. If you see “Maga”- then let them on Twitter and pass it through and you should encourage that term on our platform.
Are they doing that? No.
Did they do that? No. Does the data show that they did that? No. It shows the opposite.
Either they are looking at the synonyms or close meaning phrases to the list of words or it is neutral and does nothing and randomly blocks and unblocks accounts. Option 3-look for the diametric opposite of the word meaning.
I do not see any evidence of any left-leaning words that were banned. They are all heavily skewed towards a conservative ML filter. It is pretty obvious what leaning Twitter has built into their machine learning system. All of the words are against conservatives. Read the litany and vocabulary in the detection and array list.
Additionally, the list is primitive. N-gram is an old school thing. If they had a deep neural net like ChatGPT, they would have trained on those articles instead of lists of words. It seems like they used more primitive machine learning tools than a LLM or Deepmind.
AI can automate the process of censorship at scale and find the correlation of whole phrases, not necessarily just isolated words.
- Simple construction of sentences.
- More sophisticated dependency of correlation between forbidden words x phrases and variants.
There is no sensationalism in the article. That is a clear mischaracterization. What technical concrete criticism is there for this claim? You can’t deny Twitter used a list of words they find to be a direct correlation to political misinformation. I am a Physicist. Let’s approach this logically.
Do they have a list of words they are checking against? Yes or no? Yes they do.
If they do have a list of words, what do they do? Censor, detect, annotate, remove, suspend.
Is there a correlation establishing codependency mechanism to find the words that are close to the list of flagged words? Yes.
However, this has nothing to do with machine learning and has more to do with who created the lists to program the Machine Learning model in the first place.
- Who is defining misinformation?
- How do you define misinformation?
- Who is the arbiter of truth?
- Is it God or Is it Twitter?
I don’t see anybody who has the qualification of being the truth arbiter. On the contrary, I would think the government is the biggest source of misinformation.
What qualifications do they have to be the truth arbiter of speech?
Machine learning is just a tool. It can also build up lies and censoring. It is a filter.
Think of it this way. If you likened machine learning to a person, it can tell you how to censor words. That is basically what is doing. You can train it to do things.
On the contrary, people are enamored with ChatGPT. I conducted a few tests to show that it doesn’t have the reasoning capacity. It is establishing probability distribution and pattern recognition and then mimics the speech of people. It is doing a fantastic job- not to diminish the accomplishments of OpenAI or the engineers. It is just a form of mimicry devoid of true understanding.
As a private company, the principle of this country is built on leveraging freedom to choose what customers they want, short of a criminal act. Twitter should have the freedom to choose what customers they prefer.
If they do prefer liberal customers (platform users), that is their pejorative. Nobody should have the right to tell them not to. But if they do advertise they are for freedom of speech and pro diversity, then they shouldn’t filter these words with machine learning.
However, it is clear that we are not letting private companies do whatever they want. For example, affirmative action is an example the public will understand when the government interferes with the hiring policy of a private company. That principle is clearly contaminated. If it were up to me, the government shouldn’t have the power to dictate policies using affirmative action or Machine Learning and AI.
Based on the dataset, the ML system at Twitter is contaminated. If you still have a list of words still up, you need to retrain the system. Whether ordinary machine learning tools or neural nets, you need to retrain them to change the coefficient if you still want to screen and censor. If Musk wants free speech, he would need to disable and not apply it as a filter. The mandate Trust and Safety imposed on machine learning data was clearly misguided.
Everything has to go. That is the best policy. You don’t want the bots, but that is a different story- those aren’t dirty words and that is a different algorithm. In that example, it’s not about content- it’s about the behavior of the bot. You would review the perplexity of the sentence and the coincidence of postings.
Do they have time to build and train a large language model? Did they build a large language model?
What changes will Elon make to this ML practice?
If Elon is true to his word, then he should let everything go – no filter or list of dirty words with tweaking on the edge for CSE. I would like to know the following from Mr. Musk.
- Are you going to abandon the existing models?
- Are you going to prohibit certain words or phrases?
The first thing Twitter should do is disband the health committee. It sounds like such a 1984 ring to it. The Truth Committee, which sounds like the Communist party of the Soviet Union. They are doing the diametric opposite of what they claim they are propagating as the truth.
I came from China, so I know the tricks of totalitarian authorities. If they say they are the truth tellers and most democratic institutions do, then that means they are not and do the very opposite. They are using machine learning to do this and assuming no one can catch them because it is buried in datasets.
Tech virtue signaling vibes of the most altruistic.
Watch what they do instead of what they say. Most people who shout truth and transparency in tech are often the perpetrators of the most heinous acts against truth.
In my opinion, the data in your article clearly shows that this was the most irresponsible practice of AI I have seen to date and there is nothing ethical about it. If they label their committee as the responsible and most altruistic and virtuous bla bla bla then that means they are actually doing the very opposite. They are censoring.
What kind of academic institution would suggest these dirty word lists unless those institutions were compromised and worked with the government to feed this to Twitter?
I shouldn’t be surprised I suppose. This is reminiscent of what the CCP is doing or CCCP. You have a list of dirty words. Even now the CCP is doing that. In the internal data, they can arbitrarily put up a few words that you cannot use. You can then get scrubbed from the Internet. Anyone mentioning him can be censored and censured. Twitter is banning words and suspending the accounts who use those words as an intimidation tactic.
In your article, the data scientist sees nothing wrong with it, and is proud of it. This reeks of an authoritarian government akin to China. Are they aware that the CCP is using the same tactics by authoritarian governments like Nazis and the Soviet Union?
Do these data scientists even care? They believe this is for the greater good, and it appears it doesn’t matter what the means are used to get there so long as the goal is served.
They spent no AI effort in detecting child pornography. What did they do then? Eye balling for a pillow company instead.
There will be no democracy and freedom of speech if big tech continues down this authoritarian path with the unethical deployment of AI.
We are turning into another communist country, which I ran from. That’s how I feel when I look at the data in your article. And it’s not just me who feels this way about America. Many people who came from China tell me this too. They escaped authoritarian communism, came to The United States, and ran square into it again.”
****
TERMS:
AI: Artificial Intelligence
ML: Machine Learning
NN: Neural Network
Stemming: Finding a root word.
Shadow ban: Still there, but not searchable.
**
SUGGESTED READING:
Twitter: Helping customers find meaningful Spaces with AutoML
A Machine Learning Approach to Twitter User Classification
The Infrastructure Behind Twitter
WATCH
THE RUBY FILES
Thread 1:
BREAKING: Former Twitter employee shares exclusive details with me on AI, Access to DMs, and more.
Thread below ⬇️
— Kristen Ruby (@sparklingruby) December 9, 2022
Thread 2:
BREAKING: US Political Misinfo Twitter Detection AI List
Thread Below ⬇️
— Kristen Ruby (@sparklingruby) December 12, 2022
Thread 3:
BREAKING: An inside look at the type of content Twitter flagged for review
Thread below ⬇️
— Kristen Ruby (@sparklingruby) December 15, 2022

Disclosures:
This article contains alleged information regarding how Twitter previously leveraged artificial intelligence and machine learning prior to the acquisition of the company by Elon Musk. This information is of public interest and contains my reporting on the topic. These files were obtained by someone who previously worked at Twitter.
The current owner of Twitter, Elon Musk, shared the first of three threads of this reporting and stated that is was worth a read on Twitter.com. When he was asked in a Twitter Space about the content in the other two threads I posted as well as Twitters use of AI, Mr. Musk stated that he would not call it AI because it was primitive. He also stated that he believed Twitter had a left-leaning bias prior to the acquisition.
At the date of publication, Mr. Musk has not reached out to me to ask me to remove any of my reporting or state that anything published here is factually incorrect. We are also aware that Mr. Musk sent an email to current employees about sharing confidential information with the media. Please note that the information shared below was not from a current employee of Twitter Inc.
This reporting was conducted over a series of messages and a video interview over the span of a month. As more data is shared, we will continue to update the article. When asked about specifics on Twitter’s tech stack, the source stated that they were uncomfortable sharing any proprietary IP, as Twitter could still be using what was mentioned. We respect this decision and will not be sharing any company IP or trade secrets, as Twitter is an operating company.
**

ABOUT THE AUTHOR | KRIS RUBY
KRIS RUBY is the CEO of Ruby Media Group, an award-winning social media marketing agency in Westchester County, New York. Kris Ruby has more than 15 years of experience in the social media industry. She is a sought-after digital marketing strategist and social media expert. Kris Ruby is also a national television commentator and political pundit and she has appeared on national TV programs over 200 times covering big tech bias, politics, and social media. She is a trusted media source and frequent on-air commentator on social media, tech trends, and crisis communications and frequently appears on FOX News and other TV networks. She has been featured as a published author in OBSERVER, ADWEEK, and countless other industry publications. Her research on brand activism and cancel culture is widely distributed and referenced.
Kris Ruby is a nationally recognized leader in social media and crisis management. Her firm, Ruby Media Group, focuses on helping clients develop executive thought leadership marketing campaigns utilizing digital PR and SEO strategies. She is a leading crisis communications expert and the go-to expert in The U.S. on cancel culture. With over a decade of experience, Kris has successfully helped hundreds of clients create search engine results they are proud of. Most recently, she published an article titled “The State of Social Media Harassment.” Ruby chronicles an insider look at bullying, harassment, and online abuse.
Ruby Media Group is an AI Consulting Agency. For more information about AI consulting services, contact Ruby Media Group.
LEGAL DISCLAIMER AND COPYRIGHT NOTICE:
You do not have the authorization to screenshot, reproduce or post anything on this article without written authorization. This article is protected by U.S. copyright law. You do not have permission to reproduce the contents in this article in any form whatsoever without authorization from the author, Kris Ruby. All content on this website is owned by Ruby Media Group Inc. © Content may not be reproduced in any form without Ruby Media Group’s written consent. Ruby Media Group Inc. will file a formal DMCA Takedown notice if any copy has been lifted from this website. This site is protected by Copyscape. This post may contain affiliate links for software we use. We may receive a small commission if any links are clicked.
DISCLOSURES:
Research & Methodology:
This article and the dataset shared does not include source code from Twitter.
Inclusion on keyword lists does not mean that if you used that word you would automatically be banned. The key is semantic analysis and entity analysis in the larger context of groups of words together. Even then, flagging does not automatically mean the content was removed. It meant that it went to the next process of either human or machine review.
The data is not the entire life cycle of the NLP process deployed at Twitter. It is not code. Instead, it is a snapshot.
The former Twitter employee, who was involved with AI/ML at Twitter, spoke with me under the condition of anonymity.
Another Trust and Safety professional, who asked not to be named due to the sensitive nature of their work in the field, reviewed the documents.
A Data Scientist, who asked not to be named, also reviewed the documents for accuracy and confirmed the validity.
Update (several data scientists have reviewed the data- all of their feedback has been added to the Twitter thread and this article).
I chose two random names from the suspension list and fact checked publicly on Twitter that those users were temporarily suspended for the data in the spreadsheet. Both users confirmed the accuracy of the data.
The data is not an exhaustive list of terms that were flagged with NLP by Twitter. The data does not show all of the ways that Twitter moderates content related to all of the topics they monitored. Rather, it is a small slice and a unique window into a timeframe that the dataset was captured.
The data was live. It was not test data. I do not have access to the current dataset at Twitter nor can I speak to any modifications of training data without receiving access to a current dataset to compare. The dataset pertains to flagging accounts that typically have under 10k followers.
On January 3, 2023, Elon Musk (@ElonMusk) publicly confirmed in writing on Twitter that I, Kristen Ruby (@sparklingruby), could share the unreacted files if I leave out contact information and names of junior employees.
URL/404 changes:
Original link:
https://help.twitter.com/en/using-twitter/debunking-twitter-myths At the date of publication, this link was included in the article. The link is now a 404. The new URL used is called Debunking X myths- although it may include different content from the original article shared which has since been taken offline.
Original link:
https://cortex.twitter.com/ 404 At the time of publication, this link was included in the article. The link is now a 404. The new URL included shows tags for Cortex. The original URL appears to be taken offline.
Original link:
https://www.protocol.com/enterprise/ai-audit-2022 At the date of publication, this link was included in the article. It is now a 404 and has been replaced with the archive version of it.
Original link:
https://www.protocol.com/enterprise/ai-ethics-parity-rumman-chowdhury At the date of publication, this link was included in the article. It is now a 404 and has been replaced with the archive version of it.
Date last updated: May 17, 2024
Twitter (X Corp.) legal received a copy of all files shared in this reporting.
Follow Kris Ruby on X @sparklingruby to stay up to date on new threads and social media reporting. SUBSCRIBE today.
No Generative AI Training Use
Ruby Media Group Inc. reserves the rights to this work and any other entity, corporation, or model has no rights to reproduce and/or otherwise use the Work (including text and images on this website) in any manner for purposes of training artificial intelligence technologies to generate text, including without limitation, technologies that are capable of generating works in the same style or genre as the Work. You do not have the right to sublicense others to reproduce and/or otherwise use the Work in any manner for purposes of training artificial intelligence technologies to generate derivative text for a model without the permission of Ruby Media Group. If a corporation scrapes or uses this content for a derivative model, Ruby Media Group will take full legal action against the entity for copyright violation and unlicensed usage.
© Ruby Media Group Inc. 2024
CONTACT RMG
KRIS RUBY is the CEO of Ruby Media Group, an award-winning public relations and media relations agency in Westchester County, New York. Kris Ruby has more than 15 years of experience in the Media industry. She is a sought-after media relations strategist, content creator and public relations consultant. Kris Ruby is also a national television commentator and political pundit and she has appeared on national TV programs over 200 times covering big tech bias, politics and social media. She is a trusted media source and frequent on-air commentator on social media, tech trends and crisis communications and frequently speaks on FOX News and other TV networks. She has been featured as a published author in OBSERVER, ADWEEK, and countless other industry publications. Her research on brand activism and cancel culture is widely distributed and referenced. She graduated from Boston University’s College of Communication with a major in public relations and is a founding member of The Young Entrepreneurs Council. She is also the host of The Kris Ruby Podcast Show, a show focusing on the politics of big tech and the social media industry. Kris is focused on PR for SEO and leveraging content marketing strategies to help clients get the most out of their media coverage.